何かを思い出すということ
何かを思い出すこと、つまり記憶の想起には、目的に沿ってなされるものと、そうでないものの二種類がある。例を挙げると、微積分の問題を解くために記憶に頼る場合は前者、道を歩いていてふと懐かしい匂いがしたときは後者である。前者は合目的的、後者は無目的的あるいは反射的である。
Mr.Childrenの曲で「Another Story」というのがある。私はこの曲を大学1、2年の頃によく聴いていて、それを聴きながら歩いた道の記憶や、それを聴くとついつい思い出してしまう「あの日」や「その日」の記憶というものがある。つい一昨日、私は久々にAnother Storyを聴くと、私はそれらの記憶を想起した。それを思い出すことで、特に何かをしたかったわけではない。ただ思い出すために思い出したという方が当たっているように思う。別の目的のためでなく、あたかも思い出すこと自体が目的であったかのようだ。
合目的的な記憶の想起の場合、私は記憶に対して能動的にはたらきかけているように思える。想起の主体は私の意識であるように思われる。一方で無目的的な記憶の想起の場合には、記憶は単に「思い出される」のであって、受動的である。私がそこにはたらきかけるまでもなく、それは自然と思い出されるのだ。想起の主体は私の意識ではなく、無意識の方にありそうだ。
それでは、何かを思い出そうとして思い出せず、検索エンジンを使ってその詳細を明らかにしようとする場合はどちらなのだろう。必要な知識を引き出す役割を担うのは、私の意識でも無意識でもなく、検索エンジンのアルゴリズムである。だからこれはそもそも「想起」ではない。人間にとって、何かを覚えているということは、いつでもそれを思い出すことができるということであって、思い出せないものは存在しないといってよい。なぜなら、人間の記憶は、何かメモ紙に書き付けた電話番号のように「実体をもつもの」ではなく、思い出すたびに脳内で特定のニューロンが特定のパターンで活性化することによって「構成されるもの」だからである。音楽をダウンロードしていても、それを再生しなければ音楽としては意味をなさないのと同様、記憶は使うときに再生されなければ意味をなさない。記憶は動的な存在である。
アルゴリズムは改良され続け、最近では機械学習が導入され、これまで人間が行ってきたことが、どんどんコンピュータの手に委ねられるようになってきた。生まれてからの年月を考えれば、人工知能は人間に比べてまだまだ若輩者である。人間ができることを人工知能の手に委ねるということは、会社の比喩でいえば、中堅社員から新入社員への裁量の移動と捉えることができる。新入社員はどんどん成長する育ち盛りなのだから、いろいろな仕事を振って成長の機会を与えよう、と。
人工知能も技術のひとつである。マクルーハンがすでに指摘したように、人間は技術を利用することによって、技術に代替された能力を衰えさせてしまう。車で移動する者は歩いて移動するものよりも足腰が弱くなるし、手で書く代わりにキーボードで書く者は、手書きの字が汚くなってしまう。任せたことで、安心してしまうのだ。
先日、プログラミングで自分の仕事を自動化した社員が、しばらくは給料を受け取っていたが、ついに解雇され、解雇されたときにはプログラミングのやり方さえ忘れてしまっていたという記事*1を読んだ。自分の成果によって自分を衰えさせてしまうとはなんとも皮肉であるが、私にも似たような経験はある。誰にでもこういう経験はあるのではないか。
この筋でいくと、何かを思い出すことを機械に任せるようになると、私たちは自分の力で思い出す能力を衰えさせてしまうことになるだろう。しかし、果たしてそれだけだろうか。何かを思い出すということは、それ以上の意味を持っている。
コンピュータの学習と人間の直観
以前にも似たようなことを書いたことがあったけれども、人間はコンピュータとは違い、さいころを100回も1000回も振らなくても、それぞれの目が出る確率を6分の1だと見抜くことができる。これは直観のはたらきだ。直観というのは、すべてのデータを集めなくても、より少ないデータからすべてのデータにフィットするような規則性やパターンを見抜く能力である。これは今の所、コンピュータよりも人間の方がすぐれている。それは二段階の意味でそうだ。まずはコンピュータには問題を正しく定式化することが難しい。人間の手によってデータを適切な形に成形しなければ、コンピュータはデータを扱うことができない。そして次に、成形されたデータを使ったとしても、コンピュータがデータの背後に潜むパターンを見抜くには数千とか数万、場合によってはもっと多くのデータが必要だ。どちらも直観のはたらきに関わるが、そのいずれにおいても今の所は人間の方がうまくやってのける。
コンピュータの演算能力と記憶容量が拡大を続けるにつれて、直観を軽視するような風潮が生まれているように感じる。少量のデータでは偏りがあり、どうせすべてのデータを使っても短時間で計算できるのだったら、すべてのデータを使ってパターンを探したほうがいいじゃないか、と。これが最近はやりのビッグデータや機械学習の根底にある態度であるように思われる。ディープラーニング(深層学習)は人間の脳のはたらきを真似るものであって、人間が持つ「概念」をコンピュータにも獲得させようとするものであるから、これは直観に近づくようなベクトルだといえそうだ。けれどもこのディープラーニングでも、概念を獲得するためには人間に比べて厖大な量のデータを機械に学習させなければならない。これでは「直観とはなにか」ということがわからないままだ。
直観というのは、人間の記憶と関わっている。何を記憶しているのかということによって直観のはたらきは変わってくる。人間はものを考えるとき、頭の中にある「枠組み」(スキーマ)にしたがって考えている。スキーマは自分の経験によって獲得されていくもので、センスのいい人は少量の経験からより多くのスキーマを獲得することができる。このスキーマの獲得において、記憶というのが重要な役割をはたす。「そういえば以前にも似たようなことがあったな…」と思えるかどうかがスキーマ獲得の鍵なのだ。直観というのは、このスキーマに依存して決まる。これまでに他の誰も使わなかったスキーマによってある問題を捉え、答えを出すことができた場合に、直観がはたらいたといえる。
ここで「人間はどうやって母語を獲得するか」ということについて考えてみる。人間は自分の母語について、まだ幼いうちに習得することができる。生まれてからほんの数年の間に子どもが出会う言語データは限りがあり、しかもその中には少なからず誤ったデータ(言い間違いなど)も含まれる。しかしそれにもかかわらず、子どもはどういう言い方は文法的に正しく、どういう言い方は誤りであるかをちゃんと学習することができる。誰か特定の人間が教師として付きっ切りでサポートしているわけではないにもかかわらず、である。誤りを含む偏ったデータから、正解をちゃんとつかむことができる能力というのは、何か直観のはたらきと関係があるように思える。あえてアナロジーを使うならば、人間は言語を獲得するために必要なスキーマを、生得的に持っているということがいえるのかもしれない。このように考えたのがチョムスキーであった。彼の場合は「スキーマ」という言葉ではなく、「普遍文法」という言葉を用いた。単なるアナロジーでなく厳密を期すならば、この2つは区別されるべき概念だろう。
ディープラーニングは概念を獲得する。では概念とスキーマはどういう関係にあるか。一見すると両者は似ているようではあるが、概念が意識的に利用できるものであるのに対して、スキーマはむしろ無意識的に利用されるものであるという意味で、両者は異なるレベルに属するといえる。それではコンピュータはスキーマを獲得できるのだろうか。
私が記憶する力、言い換えれば想起する力が、私の外にある技術の結晶たちによって代替されていくとき、私は直観さえも衰えさせてしまうことになりはしないか。テクノロジー脅威論を安易に主張する気にはならないけれども、ある技術がどういう効果をもつかということについては、とくにそれが人間の人間たる所以に関わる場合には、慎重に考えなければならない。
ウェブページの読みやすさは書き手が決めるべきか
はてなブログでは自分のブログのデザインを色々と変更することができる。HTMLやCSS、Javascriptのコードを使えば変更の幅は広がるが、私はデザインを変更するときにはテーマを変えるくらいのものだ。自分にとって一番読みやすいテーマを探しては、割と頻繁にテーマを変更している。
この前「読みやすさ」ということについて考えていて、ふと思ったことがある。自分のブログのテーマは好きに変えられるのに、どうして他人のブログのテーマは変えられないのだろうか、と。せっかく面白そうなことを書いていても、残念ながらデザインが自分好みではなくて読む気が失せてしまうブログというのがたまにある。そういうとき、自分にとって読み易いようなデザインに変更できたらどれほど便利だろうか。
自分が他人のブログを読むときだけ、一時的にそのブログのデザインを好きに変えられる「フィルター」のような機能があればいいのだ。例えばSafariのリーダー機能のように、広告を排除して読みやすいフォントでページの文章を表示してくれる機能があればいい。
ウェブページの読みやすさは、書き手が決めるべきだとは、私は思わない。もちろん書き手は自分の作るページのデザインについても好きに設定したいという欲求を持っているかもしれないが、そこは紙の本と同様に、読み手にとって読みやすいスタイルに統一した方がいいのではないか。紙の本では、文章は縦書き、一ページに含まれる文字数や大きさも決まっている。それは書き手が口出しできる領域ではない。ウェブページの場合もそういう風になっている方が、私は便利だと思う。単に自分の好みでデザインを決めた結果、残念ながら読み手にとっては読む気を削がれる結果になってしまっていることは少なくないように思うのだ。
…と、ここでこの記事を終わっていては、考えが浅いように思うので、もう少し考えを進めてみる。「読みやすさ」というのは、単に読みやすいということ以上の意味をもっていると私は思う。読みやすければ、内容が頭に入りやすく、したがって記憶に残りやすく、そしてそれを使って自分なりに考えるというところまでつなげやすいということだ。鎖はこのようにつながっている。読みやすい本は、再読しようという気にもなりやすいので、内容をより深く理解したり、確認したりするのにも有利だ。読みにくい本をわざわざ読み返そうという気にはなりにくい。ここで「読みにくい」というのは、何も旧仮名遣いのオンパレードだった昔の岩波文庫のような文章を指しているのではない。或いはその分野の専門家筋だけが理解できるようなジャーゴンばかりをちりばめた文章を指しているのでもない。そういう文章ならば、こちらの訓練次第である程度は読みこなせるようになるからだ。「読みにくい」或いは「見にくい」というのは、どこに何が書いてあったかを思い出しにくいということで、後から必要な箇所だけ取り出して読み返すということがしにくいのだ。
私の頭の中に蓄えられている記憶は、私がそれについてあれこれ考えるのにしたがって内容がどんどん変わっていく。記憶は固定された情報ではなく、動的(dynamic)なものだ。なぜなら人間がものを記憶するということは、何か写真に像を焼き付けるということとは違って、思い出すたびにニューロンを発火させる必要があるという意味で「プロセス」を指すものだからだ。
それに対してウェブ上の情報というのは、本来は書き換えが自由であるとされているが、実際には書き換えが行われることはあまりない。私自身、過去の記事の文章を読み返すことはあっても、書き換えることはほとんどない。読み返すとき、記事のタイトルの横には「編集」の文字があるけれども、そこをクリックすることはほとんどない。だからウェブ上の情報というのは、特定のページについていえば、固定された情報だ。読みにくさという点でいえば、すでに述べたように紙の本の方がはるかに読みやすいと思うけれども、「そこにある情報が静的か動的か」という点で言えば、ウェブ上の情報も紙の本も共通して静的(static)だ。
固定された情報であるならば、せめて完成形が私にとって「思い出しやすい形」であってほしいと望まずにいられない。そういう形であることによって、情報が私の頭に移された後で、私にとってより好ましい形へとその情報を修正しやすくなるからだ。
どんなウェブページも、書き手と読み手の両方がいて初めて成り立つものだとするならば、その読みやすさを必ずしも書き手の側が定める必要はない。読み手にとって読みやすいこと、その選択権は、どちらかといえば読み手の方に委ねた方がいいのではないかと私は思う。
天邪鬼と知性
先日、アルバイト先で私が読んでいた本について、同僚とこんなやりとりをした。発言は正確ではないが、概ね以下のように進んだ。
同僚X:「○○さん、『ネット・バカ』読んでるんですか?」
私:「そう。この本が流行ったのは数年前なんだけど、そのときには何となく気にはなっていながら読んでなかった。以前からそうなんだけど、なんか世間で流行っているときには読んでなくて、流行る前か、流行って少し時間を置いてからしか読まないということが多いんだよね。」
同僚X:「あぁ〜、それなんかわかるような気がします。」
同僚Xが言おうとしていたのは、「逆張りの精神」とか「天邪鬼」とか言われる類のことではないかと思う。「世間がXだと思っているときに自分はYだと思えるかどうか」というやつだ。そういえば『ドラゴン桜』でも、桜木のセリフにそういうのがあった。
私は天邪鬼にはなりたくないと思っている。世間では常識とされていることの反対に実は「正解」がある、というような言い回しは天邪鬼であることを正当化するような代物であるが、厳密にいえば天邪鬼は、なにが正解であるかを判別する「知性」と直接結びつくものではないからだ。
なるほど確かに、世間が一般に不正解を選びがちであるならば、天邪鬼の人間は正解を導き出す賢者のごとく扱われることもあるだろう。何が正解かが自明ではない混迷の時代にあっては、大した考えもなしにただ天邪鬼的であるだけで、結果的には正解を選んだことになるということも頻繁に起こるだろう。「混迷の時代」という表現もまた、思考停止を招くようであまり使いたくはない表現だ。
数字を使って具体的に考えてみよう。例えば世間は様々な問題に対して、80%の確率で不正解を出すものとしよう。すると天邪鬼の人間は80%の確率で正解を出すことができる。80%の確率で正解を出せる人間は、80%の確率で不正解を出す側の人々から見れば「賢者」とみなされてもおかしくはない。ではこのとき、天邪鬼の人間に知性があるといえるだろうか。
私は天邪鬼であるよりも、自律した精神の持ち主でありたいと願う。「自律」(autonomy)というのは、他者がどう考えていようとも、それとは独立に自分の頭で何が正解であるかを考えられる性質を指す。仮にも大学を卒業した身としては、自律した思考を育むための訓練を積み、なおかつそれを錆びつかせないように磨き続けるような人間でありたいと思う。自転車のチェーンは、雨に濡れないように普段から気をつけていても、たった一回雨避けのカバーをかけそびれただけで、錆びてしまう。私の頭もそんなようなものだ。
世間の大半の人間たちがAと言おうと、ただそれだけで条件反射のようにBを選ぶ天邪鬼ではなく、自分の頭で考え、それが正解と思うならAだということもBだということもある。それは世間の大半の人間がどちらを正解だと考えているかとは関係ない。そういう風に頭を使いたい。
正解がみえにくい時代状況においては、ただ天邪鬼的であることが知性と結びつけられがちであるようだけれども、論理的には両者は本来、なんの結びつきももたない。それでも世間を見ているとネットやメディアでは批判のための批判や奇を衒うこと、目立つことばかりを考えて逆張りをしているだけであることがミエミエの、反抗期をこじらせただけのような人々がけっこういる。
何気ない生活の中でも、自分のものの考え方のスタンスを問われる局面の連続であるということを改めて感じ、その緊張感を忘れないようにしなければとも思った同僚とのやりとりだった。

 (モーニング KC)")
住宅街と図書館と、それから地球儀:モデルの意味
ロードバイクで住宅街の中を走っていると、自分のいる道と交差する道が次から次へと現れる。それぞれの道は自分のいる場所からずっと奥に向かって伸びており、その両側にはたくさんの家が立ち並んでいる。
小さい頃、図書館で本を読み漁っていたとき、あるいは単に図書館の中を歩き回っていたとき、私はここにある本のすべてを読み切ることなどできないのだということをあるとき自然に悟った。これはよくある経験である。そしてそこにある本は、世界に存在している本の中のごく一部に過ぎないということは、それからしばらくしてようやく理解した。
こんなこともある。私は保育園にいた頃、死ぬまでに世界中の国々をすべてくまなく回ってみせると思っていた。世界にいくつの国が存在しているかなど知りもせず、どこにどんな国があるかもわからなかったけれど、ただ漠然と、地球儀のイメージだけをもとに、自分の一生は長く、まだまだ始まったばかりだ。これから死ぬまでの間に、根気よくやればきっと全ての国を回りきることができると素朴に思っていた。
上にあげた3つの例のどれでも、今の私はその全てを網羅することはできないと感じるようになった。網羅とはなんだろう。世界は大きいが、自分が関わることのできる範囲はそのごく一部に過ぎない。自分の知っている、或いは知っていると思い込んでいるごく一部の範囲から、住宅街のすべて、図書館にある本のすべて、或いは地球全体の姿というものを、うまくつかむことはできるのだろうか。
さいころを振れば、私はやがて起こりうる全ての場合を網羅することができる。起こりうる場合は全部で6通りで、しかもそれらは起こる確率が互いに等しいのだから簡単だ。地震はどうだろう。起こりうる地震というのをマグニチュード0(地震なし)からマグニチュード8くらいまでで考える。サイコロの場合よりは起こりうる状態の数が2つ増えた。これだけならまだいいが、地震の場合はそれぞれのマグニチュードの起こる確率が互いに等しくない。マグニチュードの大きい地震は滅多に起こらず、日本人の中でも、生きている間にマグチチュード0から3くらいまでしか経験したことのない人というのも過去にはいただろう。
もしも全ての状態を網羅していないとしたら、自分の経験の中には存在しない出来事があるとしたら、人間は、そういう未経験のことがらについても、既知のことがらから正しく連想を行って理解することができるのだろうか。そういうことは震災の後で私たちが問われた問題だった。つまり、実際には東北の震災を直接経験はしていない多くの人々が、それでも震災を経験した人々に対してうまく想像力をはたらかせることができるかどうか、そして被災者とうまく助け合うことができるかどうか、という形で。
ロードバイクで自分の走る道は、ありうる全ての道の中の1通りにすぎない。気分を変えようと考えて、違うコースを開拓したとしても、まだまだ十分でない。残されたコースは依然として残る。それでも私は、走っている道と、その周りに広がる街とをうまくつなげて捉えることができるだろうか。
常に全体の中の一部にしかアクセスできない自分が、それでも全体について想像し、全体についてより正確な像を得ようとし続ける。Googleを使っても、全体像を捉えることなどできはしない。いや、場合によってはむしろ遠ざかると言ってもいいだろう。全体像を捉えるための深い思考を、それは妨げることがあるからだ。
全体そのものを構成することはできない。だから私たちは全体の模造品を頭の中に形作る。その模造品は「モデル」と呼ばれる。モデルは確かに不完全だ。それはモデルとして不完全という意味ではない。それはかつてボルヘスが「学問の厳密さについて」*1の中で描いた、世界と同じ大きさの地図ではないという意味で完全ではない。しかしそんな意味で完全ではないということに何の意味があるというのか。世界はサイコロよりもはるかに複雑で、到底網羅などできはしない。どれほど記録をとり、どれほどのデータを高速に大量に処理したとしても、世界と全く同じものを構成することはできない。
部分と全体が、うまく一対一に対応しない。リンクの失われた箇所があって、しかもそれは少なくない。それでも全体についてのイメージを描こうとする。今日もいつもと同じ道を使って家に向かう。
*1:
")
- 作者: J.L.ボルヘス,Jorge Luis Borges,鼓直
- 出版社/メーカー: 岩波書店
- 発売日: 2009/06/16
- メディア: 文庫
- 購入: 5人 クリック: 27回
- この商品を含むブログ (47件) を見る
ランキングと記憶と銀行について
私は時々、順序がつけられる前のウェブというものがどんなものだろうと考える。莫大な情報がなんの秩序(order / pattern)も持たずに散乱している広野のようなウェブ。検索エンジンが、ニュースキュレーションアプリが、或いはSNSが、私個人に最適化したランク付けをする前の、雑然としたページの大群、あるいはジャングルを自分で探検してみたくなるのだ。そのときの「探検」というのは英語で言えばsearchというよりもexploreの方が近いかもしれない。私はInternet Explorerは全く使わないが。
ウェブ上で目にするページの多くは順序がつけられた後のものだ。情報が多すぎるのだからこれは当然といえば当然かもしれない。探索するには情報が多すぎるために、検索エンジンといえば「ページのランクづけをするもの」ということにもなる。
「ネットサーフィン」という言葉がある。最近はあまり使われなくなった言葉だ。それは裏を返せば、ネットサーフィンという行為を支えるテクノロジーが、生活の中に浸透していって、多くの人々が、呼吸をするのと変わらない感覚でネットサーフィンを行うようになったことの裏返しなのだろう。「私は今まさに呼吸をしている」とわざわざ口にする人間はいない。
さて、サーフィンをするためには、波にうまく乗らなければならない。それも自分のすぐ近くの波に。遠いところにある波に乗ることはできないのだ。乗るべき波を見つけることを実現しているのが検索エンジンだとするならば、もしもそれなしでウェブの海へ出れば、私はウェブに飲み込まれてしまうだけかもしれない。波には近いものも遠いものもなく、いろいろな方向の波が混じり合い、どの波に乗るべきか、どういう風にすれば波に乗ることができるのかわからずに、ただただサーフボードとともに海にのまれるだけになってしまうかもしれない。
ネットでExploreするということ
ところで、そもそも私はウェブで「サーフィン」をしたいのだろうか。ウェブ上でできることというのは、サーフィンだけなのだろうか。なるほどインターネットは情報の海であって、その中で移動するのであれば「サーフィン」という言葉で表現するのが適当かもしれない。しかし、そもそもネットという空間を喩えるのに、「海」しかないのだろうか。海以外の、そしてサーフィン以外のいい比喩はないのだろうか。冒頭では"surf"の代わりに "explore" という言葉を使ってみた。
Internet Explorerは、かなり初期からGoogleを使うことによってexploreする人が多かったから、"Explorer" のようで実態は "Searcher" になっているといえる。それでは言葉の本来の意味での "Internet Explorer" はどこかにあるのだろうか。ネットで何かを探すときには、当然のように検索エンジンが使われるようになり、今やその大半がGoogleによって行なわれている状況では、Searcherばかりになっているのかもしれない。何かを知ろうとして検索ボックスに調べたい単語を入力するとき、私たちは当然のようにページのランク付けをGoogleに依頼することになる。
検索エンジンは図書館の「司書」(librarian)を参考にして、検索者が最も欲しがる情報を的確に探し出すことを目的として設計された。それは今も基本的には変わらない。検索エンジンの後でSNSが登場し、こちらは利用者の人脈を広げるだけでなく、その人脈を使って欲しい情報を探し出すという方向でも発展してきた。
ウェブというのは「蜘蛛の巣」であるから、検索エンジンとSNSでは後者の方がウェブと相性がいいという見方もできるように思う。情報の網(ウェブ)を、人間の網(ソーシャルネットワーク)を使って探し出すわけだ。今でも、何か知りたいことがある場合、検索エンジンを使うよりも「しかるべき人」に相談した方が、自分の欲しい情報を探し当てられることが多い。例えば私はロードバイクであちこちを走り回るが、見知らぬ土地へやってきたとき、Googleマップを使って経路を考えるよりも、その土地の住人に道を聞く方が、具体的な経路をイメージしやすかったりする。
ExploreとMemory
先日は割と分量のある文章で、グラフとランク付けの対応を中心にして検索エンジンの意味というものを考えた。SearchではなくExploreを行うためには、ネットを使うにあたってすっかり浸透しきっている「ランキング」というものから一度離れなければならない。
plousia-philodoxee.hatenablog.com
グラフをランク付けのリストに変換したりするのは、人間の記憶(memory)のしくみと関係があると私は思う。ここからは、記憶と言っても「長期記憶」に限定して話を進めていく。完全記憶を持つ人間は、自分の経験した出来事や見聞きしたことなどを何ひとつ忘れることができず、苦しむことになる。記憶というと、「覚えること」の方と結びつけて理解されることが多いが、これでは片手落ちであって、忘れることの方も同様に重要であると考えなければならない。何を覚え、何を忘れるかという選択によって記憶が成立しているというのが、少なくとも生物にとっての記憶の意味ということになるだろう。覚えることと忘れることは記憶という一枚のコインの裏表をなしている。
ランク付けのリストというのは、いわば人間の記憶の「代わり」なのではないだろうか。多くの人間が検索結果の1ページ目しか参照しないのは、多くの人間にとっては、思い出せる情報の量が検索結果1ページ分と対応するほどの量であるということなのではないか。私にはそんな風に思える。2ページ目以降はほとんど参照されなくても、存在していることがわかっていると、それらも自分の記憶と地続きであるかのように錯覚してしまわないだろうか。本当はそんなことは全くないにもかかわらず。
検索エンジンでは、たとえ私たちが見ないとしても、200位と201位のランキングが行われている。その二つのページのランク付けは、私たちの多くにとって意味をなさない。それは私たちがものを考えるときに思い出されないでいる事柄どうしの順序を問題にしている。
プラトンの『パイドロス』の中で、ソクラテスは彼の知人パイドロスと木陰で始終語り合う。対話の中で、人間が文字(書き言葉)を使って考えを記録しておけるようになったことによって、記憶力が衰え、ひいては思考力が衰えてバカになってしまうのではないかという懸念を示す場面がある。これは書き言葉に対する話し言葉の優位という文脈で論じられることもあるが、ここではこれとは別の文脈、つまり検索エンジンとの関係から考えてみたい。検索エンジンが、基本的には文字によって記述されたページの解析によって成立しているのは、パイドロスにおけるソクラテスの弁の意味では、人間の記憶と逆行する皮肉のようでもある。こうして「ネット検索は我々をバカにする」だとか、「ネット検索をする者はバカ」*1といった議論が生まれることにもなる。あるいは「記憶の外部化」という形で論じられることもある。
「長期記憶」に絞って話を進めてきたが、人間の記憶には短期記憶もある。人間がものを考えるとき、時間が経ってもいつでも思い出せる記憶(長期記憶)だけに基づいて考えを展開していくわけではなく、一時的に記憶している事柄も使って考えることはできる。ネットで何かを検索する時にも、この一時記憶に頼ったりする。一時的な保管庫に新しい情報を蓄えていって、それらと長期保管庫の情報を組み合わせて思考を展開しているというのが人間にとっての日常の思考の実態なのではないだろうか。
記憶を蓄えておく場所を指して「保管庫」と表現したが、これは「預金口座」に喩えることもできる。多くの人は、実際にはどんな金額でも預けることができるとしても、一定量の金額しか口座には預けない。もちろんそれはその預金額に比例する所得を稼ぐ人が多いからであって、人々がもっと多くの金額を稼ぐようになれば、それに応じて平均的な預金額も増えることになるだろう。しかし比例定数は増加しない。所得の3割を貯金する人は、稼ぐ金額が増えても貯金する割合は3割のままだろうと思われる。
教養とExplore
すぐに引き出して使うことのできる知識を「教養」と呼んだりすることもある。単に「知っている」だけの状態では、いつでも引き出して使いこなすことができる状態とは違い、それでは教養があるとは言えない、と。教養というのは本をたくさん読めば身につくというものでもない。それは言い換えれば、情報量を増やしても教養が身につく保証はなく、1冊1冊の本を丁寧に読むことによって、それほど多くの本を読んだわけではなくても、ちゃんと「教養」と呼べるものを身につけている人もいる。教養は本の読み方に依存して決まる。教養にもとづいてものを考えられるようになるためには、ある程度の集中力が必要になる。一定の範囲に限定して、その中だけで活字を追っていく。そして同時に、自分の頭をはたらかせて考え続けることで、初めて教養が身につく。そしてこれは、記憶と結びつけて考えるならば、長期記憶の領域の情報だといえる。一時的に吸収して利用するものを教養とは呼ばない。文字どおり、その人の血となり肉となっていなければならないのが教養である。
それでは、人間の持つ記憶と、ランキングが「資源の有限性」を媒介にして結びついているのだとしたら、ランキングから距離を取るのはそう簡単ではない。しかし、預金口座の比喩や教養について言及した箇所で述べたように、人間は長期記憶だけでものを考えているわけではなく、一時的に記憶した情報を使ってものを考えることもできる。ネットで検索をすればするほど、私たちは長期記憶をおろそかにするようになる。長期記憶をおろそかにするということは、その領域で醸成される教養にもとづいてものを考えることをおろそかにすることにもつながる。ネットがどんどん普及すればするほど、巷の書店では「教養本」があふれかえるようになっているのは、無関係ではない。ネットを使っていても教養は身に付かず、したがって体系的にものを考える術が身に付かないために、教養を身につける必要性は高まるのだ。
人々はどこかから引き出してきたお金を、まるで自分のお金ででもあるかのように扱い、預金口座に預けられている金額は一向に増えない。ネットを使うということがそういうことにしかならないのだとしたら、これほど情報が溢れかえっているというのに、なんという大いなるムダであることだろうかとすら思う。預金口座の残高を増やし、そこに作り上げられていく教養の樹を豊かにしなければ、たくさんの情報を簡単に集められても一向にものを考えられるようにはならないだろう。
*1:
即座に思いつく文献をあげると次のようなものがある。もっとも、この本のどちらも直観的に「ハズレ」のような気がして、私は読んでいない。私個人にとっては「筋の悪い議論」としか思えなくとも、ある程度は世間の中で話題になっているテーマではあるらしいので一応取り上げた。
")

主観的なランキングと客観的なランキング
Googleは当初、厖大なウェブページの客観的なランキングを行っていた。誰が見ても同じページは同じ順位にあって、新しいページが加わればランキングは更新されるが、それはランキングを見る人間とは独立に生成されるものだった。やがてランキングは「パソナライゼーション」という言葉で表現されるように「検索する個人」をランキングと結びつけるようになった。客観的なランキングから主観的なランキングへ、みんなにとってのランキングから私にとってのランキングへ変わった。今もランキングの「主観化」は続いている。
私は普段、ほとんど音楽を聴かない。だから音楽のジャンルや最近はやりの音楽などはちっともわからない。そんな私が、ネット上でたまたま見つけた音楽にハマるということがたまにある。いや、私が新しい楽曲を見つける時はいつも、私とは別の誰かのフィルターを通している。
ランキングというのは、私にとってのランキングであるよりも、他者にとってのランキングを参照する方が、面白いということなのではないか。しかし、それならば一体誰のランキングを参照すればいいというのか。私ならばここに一人しかいないけれど、他者となると厖大な数になってしまう。「信頼できる他者」という表現がすぐに浮かんでくるが、では信頼できるかどうかをどうやって判別するのか。たとえばこのはてなの世界は、ある程度のリテラシーを持つ人々が集まっていると当初からみなされているようなところがあって、それはアメーバブログに集まる人々とはタイプ的に異なる。どちらを参考にするかは個人によって異なる。
しかし、私が参考にしているのは他者にとっての主観的なランキングなのだろうか。他者は自分なりのランク付けを何らかの方法で実行し、それをウェブ上に公開し、それを利用することによって、セレンディピティー的な出会いがもたらされ、私はハッピー…という筋書きが正しいのだろうか。
Googleで検索するよりも、はてなで検索する方が面白いページに簡単に出会うことができるので、最近はもっぱらはてなでの検索を行っている。もっともはてなの検索はPowered by Googleなのであるが。そして今日も、大崎駅の近くのスターバックスにて、「検索エンジン 数理」といったキーワードで検索していると思わぬ形でこんな記事を発見した。
検索エンジンは、線形代数に支えられているという見方もできるが、グラフ理論に支えられているという見方もできる。そして線形代数とグラフ理論の間には密接なつながりがある。上記のキーワードで検索したのだからグラフ理論について扱ったページがヒットしたのもうなずけるが、なんとこのページで扱われている内容のほとんどはアブナー・グライフの『比較歴史制度分析』である。 ある情報が信頼に足るものであるかをどうやって判断するかということについて、人間はどのような「しくみづくり」をしてきたのかということを簡潔にまとめてあって、とても面白かった。
")
- 作者: アブナー・グライフ,神取道宏,岡崎哲二
- 出版社/メーカー: エヌティティ出版
- 発売日: 2009/12/09
- メディア: 単行本(ソフトカバー)
- 購入: 3人 クリック: 270回
- この商品を含むブログ (22件) を見る
Amazonで探すと、もはや中古でしか手に入らないらしい。新品にこだわる私としては残念であるが、とりあえず書店で探してみようと思う。
さて本題に戻ると、このページははてなの検索ではかなり下位の方にランキングされていた。「SEO対策バッチリ!」だとか「ちゃんと記事の最上部にいい感じの画像を貼って…」だとかをしない、内容だけで成り立っているページだから無理もないかもしれない。はてなで面白そうなページを探すとき、私は検索結果の10ページ目まで見ることにしている。ここまでくると、もはやランキングには意味はない。「私にとって面白いかどうか」ということとランキングは全く別次元のように考えているからだ。
もっとも、はてなの場合、ランキングはどれほど厳密に行われているのかはわからない。単に検索キーワードが含まれるページを表示しているだけかもしれないと思わないでもない。
私にとって、面白いページはランキングとは関係なく決まっている。それならばランキングになんの意味があるというのか。
どうやって「それ」を見つけ出せばよいか。どうやって "This is it !!" を実現するのか。ランキングが客観的なものから主観的なものへ変化しても、依然としてそれは「ランキング」であることに変わりはない。「検索=ランキング」パラダイムは揺るぎないということか。
面白いページを見つけたいとき、ランキング以外の方法でそれを実現することはできないものか…。最近はこの問題をずうっと考え続けている。なかなかすっきりした解にたどり着かないのは、一つには私がこの問題を何らかの形で定式化できていないことが原因だろう。問題を適切な形で定式化するためにはそれなりの専門知識と技量が必要とされるが、そのどちらもまだ私は十分に持ち合わせていないということだと思う。
路線図:駅:街→私
(東京の路線図。なんとまあ複雑なことよ。)
はじめに言っておくと、この記事は路線図と街の関係について書いているようで、実はそうではない。テーマが何であるかは読み手の方々の想像にお任せする。そんなにもったいぶるほどわかりにくい比喩でもないとは思いつつ…。
人気の駅と人気の街
路線図を観察していると、たくさんの利用者がいる駅にはたくさんの路線が通っていて、その周辺部は栄えていることがわかる。路線図は数学的には「グラフ」(無向グラフ)として扱うことができるから、その構造を分析する事によって、特定のノードとしての「駅」が、すべての駅の中で何番目に優れているかといったランキングを作ることができる。
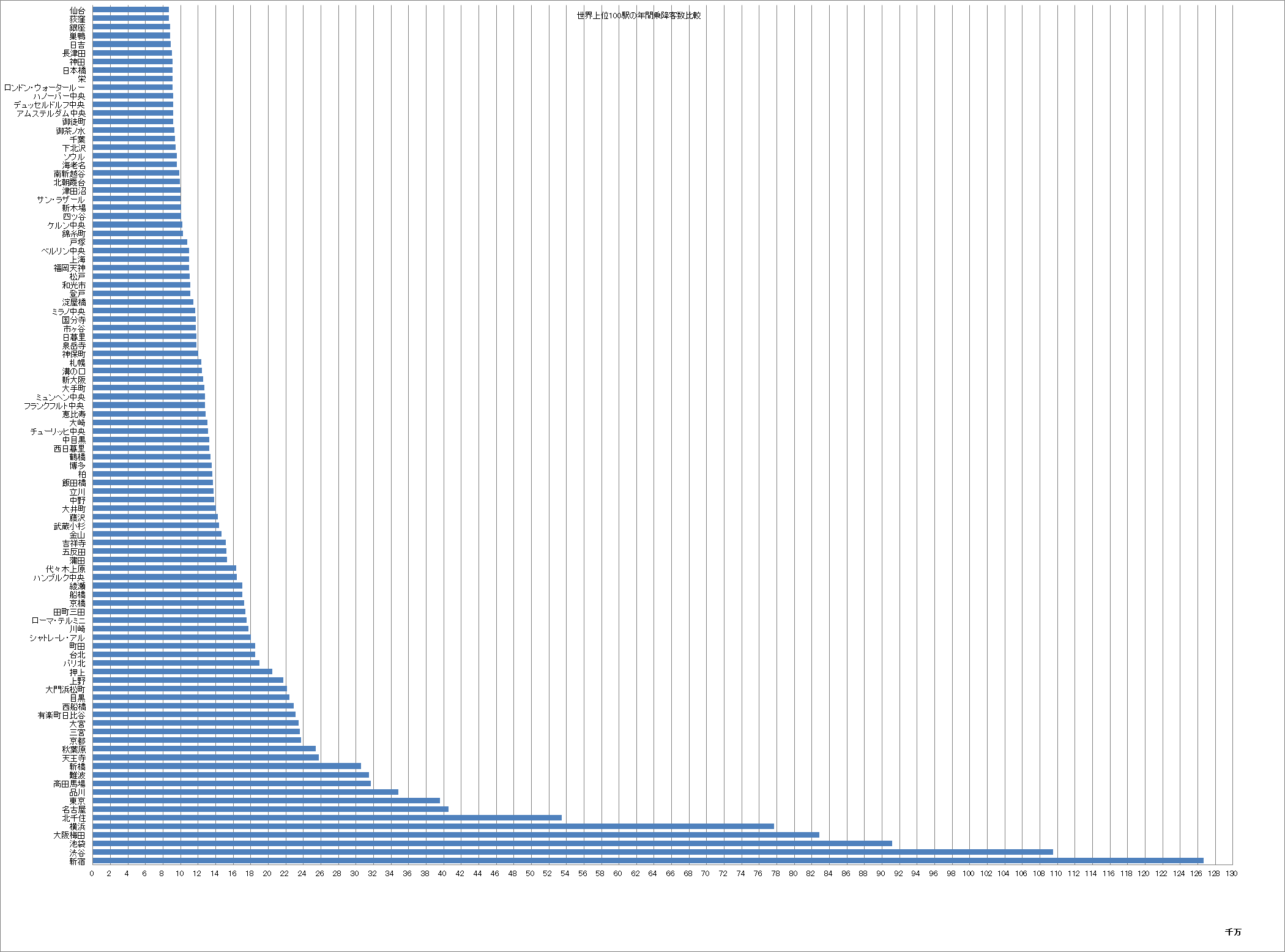
(世界上位100駅の年間乗降客数ランキング。なんとすべて日本の駅。
出典:世界上位100駅の年間乗降客数比較、日本だらけでワロタwwwwwwww : はちま起稿)
ここで、「優れているとされる駅の周辺は、街として繁栄している」という正の相関関係があるならば、駅のランキングを行うことによって、私たちは間接的に街のランキングを行っていることにもなる。「優れている」ということには何らかの価値判断が入るけれども、特定の価値観を反映したランク付けでは客観的とはいえないので、なるべく恣意性の入り込む余地のない形でランキングを行う必要がある。
そこで考えられるのは、冒頭に述べたように、多くの駅とつながっている駅のランクを上位にもってくるという方法だ。この方法を使えば、特定の誰かが大量の「サクラ」として、「あの駅いいよ!」と声高に主張していたとしても、そういう特定の個人の評価だけに左右されずに、多くの人間の評価の最大公約数をとって、より公平なランク付けを行うことが可能になる。
ここで、「自分はどこに住むべきか」を考えている人物Aと人物Bがいたとする。彼らはこの「駅ランキング」を参考にして、その駅が最寄駅であるような場所に住もうと考える。Aにとっての「いい街」とBにとっての「いい街」は、上のようなランク付けの方法では同じになるだろう。しかし個人から見れば、最大公約数的な「いい街」と自分の考える「いい街」とは必ずしも一致しないという問題に直面する。そこで、ランキングを行う企業Gは、ランキングを利用する人間の個性をランキングの結果に反映するようなランク付け方法の改良を行う。ただし、グラフ構造からランク付けを生成するという前提は崩さずに。
点と線のかたまり、或いはリスト
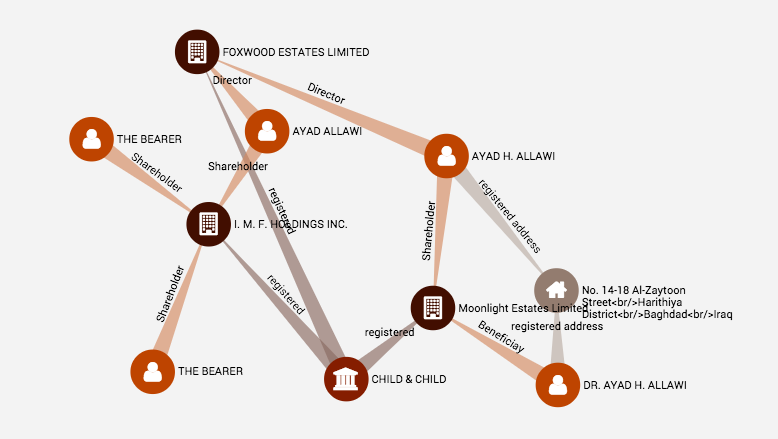
(最近話題のパナマ文書に関する、株主や取引関係を示したグラフ。
出典:パナマ文書の取引や株主の情報がグラフ構造として公開されてるらしい - データの境界)
何かをランク付けしたければ、それについてのグラフがあればよい。そのグラフの構造を分析すれば、ある特定のノードがグラフ全体の中で何位にランクインしているかがわかる。点と線のかたまりは、一定の手順で処理されたのち、リストに変わる。
点と線のかたまりも、リストも、その背景には「競争」(competition)がある。点と線のかたまりにおいては、かたまりの中でたくさんの線が延びている点が優秀ということになるし、リストにおいては、上にきているものほど優秀ということになる。競争で勝ったものこそ、より多くの人に知られるべきであると。
競争というメカニズムは、よりよいもの、正しいものを選び出すアルゴリズムになっていて、より長い時間経過の末に生き残ったものは価値が高いとされる。逆に淘汰されたものは、知られるべきものではないとされ、点と線のかたまりでは周縁に位置付けられ、リストにおいては下に回される。リストは、やるべきこと(ここには「買うべき食材」だとか、「手をつけるべきタスク」だとか、いろいろなものが当てはまる)を考えるときに最もよく利用される。

(一般的(?)な買い物メモ。
出典:たぶん誰もやってない「買い物メモ」の書き方 - mind and write)
買うべき食材をリストにまとめるとき、私たちは当然のように、今すぐ必要な食材だけをリストアップする。すぐに必要のない食材をわざわざリストに書く人はほとんどいないだろう。スーパーに行ったところで今すぐは必要でない食材を買ったりはしないからだ。これはまるで、検索結果の1ページ目だけを見るという行為のようだ。いや、「AはまるでBのようだ」と言うよりも「AはBと同型である」と言う方が正確だろうか。どちらも、私たち人間の「注意力」という資源に限りがあることに起因する現象だ。そして言葉の定義上、全てに対して注意を払うことはできない。一部に対して払うからこそ、注意は注意として十全に機能する。
ランキング→グラフ
ある特定の構造をもつグラフを、一定の手順で処理することによってランキングという別の表現に変換することができるのだとしたら、その逆の処理は可能なのだろうか。つまりランキングを与えられれば、そこから特定の構造をもつグラフを生成することはできるだろうか。これはおそらくできる。それでは先ほど登場した買い物リストは、グラフに変換することができることになる。リストの上位にきている食材ほど、よく使われる食材という事になるだろうから、ある個人の買い物リストを長期にわたって収集すれば、それを可視化したグラフから料理の傾向がある程度明らかになるだろう。これは街と路線図の間にも同様に当てはまることだと思われる。つまり、ひとたび街のランキングを作ってしまえば、そこからまずは駅のランキングを生成した上で、上位の駅がたくさんの駅とのつながりを持つようなグラフを生成することができるだろう。なるほどこのように考えてみると、グラフとランキングの結びつきは強固であって、そこには切っても切れない「腐れ縁」や「運命の赤い糸」のようなものすら感じさせる。
XとYには一対一の関係が成り立つ時、その「対応のさせ方」のルールさえわかっていれば、どちらか一方から他方を復元することは難しくない。グラフからランキングを、或いは逆にランキングからグラフを生成することができる。まるでDNAの二重らせん構造のようだ。ただしそのルールは、人物Aも人物Bも詳しくは知らず、ただベターな解判定の仕組みとしての「競争」に対する素朴な信頼が、ランク付けの大規模かつ継続的な利用を支えている。
注意を向ける範囲には限りがあって、競争というものがその範囲をうまく決めてくれるのだとしたら、人間が、競争というメカニズムに沿って、自分の注意を向けるべき対象をうまく限定することには一定の合理性があるように思われる。競争は歪んでいるかもしれないし、勝者総取り(Winner-Take-All)という固定化が起こりやすいとしても、競争に対する信頼はそう簡単には揺るがない。もちろん一部には競争というメカニズムに対して懐疑的な人間もいて、そういう人間たちは自分の目で下位の駅の調査も行う。ランキングの主導権を、「あちら側」から「こちら側」に持ってこようとする。それはまるで、食べログには載っていない隠れた名店を探そうとするグルメたちの行為のようでもある。いや、同型である。
競争を利用したランク付け
よりよい解を判定するために、競争というメカニズムはいたるところで利用されている。いや、「利用されている」などと書くと、人々が意識的に競争という方法を選択したかのように響くけれど、実際には自然発生的に競争状態が生じることがほとんどである。
私自身、学部時代には経済学を学んでいたから、市場における競争のメカニズムによって、いかに効率良く資源(商品も含む)が配分されるのかということについて学んだ。効率的な資源配分が競争というメカニズムによって達成されるためにはどんな条件が必要であるかということは経済学の基本的な問題であって、「その条件というのが現実には当てはまらず、したがって経済学など所詮は机上の空論に過ぎない」という論調も何度となく目にしてきた。情報は完備(complete)でも対称(synmetric)でもないし、市場は完全競争(perfect competition)ではないではないか、と。
それでは経済という領域において、よりよい商品が市場に出回るようにするためには、競争以外に何かいいメカニズムはあるのだろうか。政府の介入によって市場の不完全性を補完するという立場がひとつある。けれども実際には介入が失敗することも少なくなく、人々は失敗のたびに政府による介入に懐疑的な姿勢を強める。政府に任せようとする考えが生じるのは、調整を行う力を持っている主体が政府であるからだということだと思われるが、本当に政府だけだろうか。合理的な調整を行う力があるならば、それを実行する主体が政府である必要性は消えてしまう。「その時、政府は…」という政治学の問題はここでの議論からそれるので考えないことにしよう。
ランキングの方法が完全でない場合、それをうまく調整できるやつが調整すればいいじゃんという考え方を採用するとして、「調整」というのは順位の調整でなく、結果の調整である。もちろん順位を調整するという考え方もあるが、それは「結果の調整」という問題の側から見れば、副次的な問題にすぎない。駅と街の問題の場合、複数の駅を一つにまとめることは難しいけれども、もしも調整にかかる摩擦が少ないならば、思い切って複数の駅を一つにまとめてしまった方がよりよい結果になる場合だってあるだろう。私は普段、通勤に井の頭線を利用しているが、駅と駅の間隔は他の路線よりも短く、思い切って駅の数を減らした方が利用者にとっても都合がいいのではないかと思う時がある。もちろん現実には摩擦が大きすぎてこれは不可能だろう。しかし可能なのだとしたらやるべきだという風に考えてみることにはそれなりの意義がある。少なくとも、この記事の冒頭に述べたように、それが駅と街の関係の問題のようでいてそうではないのだとしたら。
この記事のテーマに関係する、これまでの自分の問題意識を表現した過去記事たちを、ここでまとめて添付しておくことにしよう。備忘録として。
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
ゲームとメタゲーム
たいていのゲームには、「そのゲームに勝つ(負ける)ことによって」という形で勝敗が決まる「メタゲーム」が存在すると私は思う。親が自分の子どもとの勝負(何かもっと具体的な例を挙げるべきなのだが、あいにく思い浮かばない。各自で適当なものを当てはめてみてほしい)でわざと負けてやるとき、それは親が「親としての役割を果たす」というメタゲームでは勝ったことになるし、逆に親が子供を完膚なきまでに負かしたとしても、それで子どもが自信を失ってしまったりなどしたら、それはもうメタゲームでは親の負けだ。この場合はゲームでの勝敗とメタゲームでの勝敗が逆転しているが、両者の勝敗が一致する場合もある。子どもがはまっているテレビゲームで親子が勝負する場合、親がテレビゲームに勝てば、子どもからの尊敬や信頼を勝ち取ることによって、メタゲームでも親の勝利と考えることができる。
このゲームとメタゲームの関係を表す文句に、「勝負に勝って試合に負ける」というのがある。勝負がメタゲームに対応し、試合がゲームに対応すると考えればよい。
頭のいい東大生が、なぜか世間からの評価は低かったりするのは、ゲームには圧倒的な勝利を収めていても、メタゲームの方では負けてしまっている場合が少なくないということの表れなのかもしれない。こんなことを書くと語弊があるかもしれないが、どうもそういうことなのではないかと思う。例外となる人々もいるにはいるが他の大学の場合に比べると割合は低いように思う。ゲームに没頭しているうちに、実は同時進行しているメタゲームの存在に気がつかないままゲームが終わってしまったということなのではないか。
もう一つ、「あの人悪い人ではないんだけどね…」と他人から言われている人や、「あの人優しいんだけどね…」と言われている人なども、「人格者ゲーム」では勝ちかもしれないが、それと同時進行する「恋愛ゲーム」という名のメタゲームでは負けてしまっているのかもしれない。人格的に優れていれば、恋愛がうまくいくわけではないけれど、それでも人格が優れていることにこだわってしまったりする「優等生タイプ」の人などは、大変だろうなと思ったりする。私にもそういうところはある。こういう場合に注意しなければならないのは、人格者ゲームで勝つこと=恋愛ゲームでの勝利という風に考えてしまったり、実は人格者ゲームで戦っていることになっているのに、自分では「これは恋愛ゲームだ」と勘違いしてしまっているような場合だ。ゲームとメタゲームを混同してしまうと、冒頭で述べたように両者の勝敗が逆立する場合はメタゲームの方で負けてしまう。もちろん、人格者であることによって、恋愛もうまくいく人もいるだろう。ただし、それはサッカーや将棋やポーカーのようなゲームのように、勝ち負けが明確に判定可能というわけではない。メタゲームの勝敗は曖昧だ。
ゲーム理論では、ゲームに勝つための有効な戦略が説かれている。それはメタゲームの戦略を考える際にも役に立つことはあるだろう。しかし、ゲームとメタゲームの勝敗の関係は自明でないから、しっぺ返し戦略や裏切り戦略などを活用しても、メタゲームでは負けてしまうということがありうる。
私は今、どんなゲーム、どんなメタゲームのフィールドの上にいるのか、そしてちゃんと戦えているのか、とふとそんなことを思った。
【追記】
この記事をFacebookに投稿したら、大学時代の友人からコメントをもらった。それについて少し説明が必要だと思われるので、ここに追記しておこうと思う。メタゲームの勝敗というのは、それを評価する人間の主観に左右されるところがあるということだ。ゲームの方はルールが厳密に決定されていて、それにしたがって勝敗が決まるが、メタゲームの方はルールが厳密でない場合が多く、何をもって勝ち(負け)と判断するのかが明らかでないことが多い。だからあるゲームの勝者が、Aにとってはメタゲームの勝者と移り、Bにとっては敗者と映るというようなことはままあることだ。分かりやすい例は起業家の評価であろう。ビジネスで大きく成功したのであれば、ビジネスというゲームにおいては勝者と考えて問題ないだろうが、それが「ビジネスの成功によってその人はどういう人間であると思われるか」という形のメタゲームにおける評価となると、ある者は彼を資本主義システムにおける勝者にとどまらず、人生における勝者と見なして羨み、ある者は彼を資本主義システムにおける拝金主義者と見なして人生においては成功しているとは言い難いとみなすだろう。このときメタゲームにおける勝敗は、個々人によって評価が分かれることになる。だから、もしも自分がゲームのプレイヤーの立場である場合には、問題はメタゲームの勝敗を評価する人間の「ものさし」を知っておくことだろう。
サイコロが人とAIを振り分ける
サイコロの各目の出る確率を考えるとき、人間は何度も繰り返しサイコロを振らなくても、極端な話、一度もサイコロを振らなくても、それぞれの目が出る確率が6分の1であることを見抜くことができる。これを「直観」と呼んでいる人も多い。少数のデータから答えを見つけ出すことと言い換えてもいいだろう。以前、統計に基づく処理を行う自然言語処理では、大規模な集団のマクロな傾向は分析することができても、個別の人間の特性を推定することは難しいということについて触れたことがあった。
plousia-philodoxee.hatenablog.com
これに対して、もしも人工知能が同じ問題に対処するとしたら、とにかくサイコロを実際に振ってみて出た目のデータを処理して統計的に6分の1という確率を弾き出す。だからもしも一度もサイコロを振らなければ、或いは少ない回数のデータしかなければ、人工知能は統計が使えないから、サイコロの出る目の確率を正しく答えることができない。この意味では人工知能には直観がない。
ただし、確率を計算するための大量の結果だけがわかっている場合には、人間が計算しても人工知能が計算しても大した違いはない。人間が人工知能と同じ確率をちゃんと計算できたとしても、どうしてその確率になるのかという「メカニズム」の方はわからないからだ。サイコロの場合であれば、サイコロの面の数は6面あって、それぞれの面が上にくる確率は互いに等しいとすぐに見抜くことができたから、一度そのメカニズムさえわかれば答えを出すのは容易かった。
すると、直観というのはメカニズムを見抜くことと何か関係があるのかもしれない。ここで「関係がある」という断言を避けているのは、少なくとも私個人の場合、何かが直観的にわかったという場合、メカニズムがわかっている場合と、わかっていないけれどもなぜか答えはわかるという場合の両方があるように思えるからだ。IQテストのようなパターン認識系の問題の場合なら、メカニズムがわからなければ原理的に解けないようになっているから、直観とメカニズムの認識は不可分に結びついている。しかし、例えば街中を歩いていて、「なんとなくこっちに行った方が近道だという感じがする」というような場合には、メカニズムはよくわからないまま直観だけが生まれている。
「ディープラーニング」(深層学習)の研究が進み、人工知能が大量のデータから何らかの「特徴量」を取り出すことができるようになった。それは人間がこれまで「意味」と呼んでいたものと同じなのではないかと考える人もいる。サイコロの例でいえば、人工知能もサイコロが6面あるということを大量のデータから理解することができるようになったという風にいえる。しかしそのためには「大量のデータ」が必要なことは変わらない。量を質に変えるためには、そこが前提条件だ。だから逆に、少数のデータから特徴を取り出すことは相変わらずできないままだ。
いまここに、十分な量のデータがそろっていれば、人工知能の方が早く正確に答えを出すことができるかもしれない。しかしデータの量が少ししかなければ、人工知能は早く間違った答えを出す可能性が高い。データの偏りが原因である可能性もあるが、何よりも少量のデータからメカニズムをつかむことが、機械学習では不可能であるからだ。たとえばここに普通の6面サイコロと、8面サイコロの二つがあり、それぞれ10回ずつ振ってみたとする。どちらも1〜6の目しかでなかったとしたら、人工知能は6面サイコロと8面サイコロを区別することができない。人間ならば、一目見ればたちどころに両者を区別できる。これが10回でなく、100回とか1000回のデータであれば、8面サイコロの方で7や8の目が出るはずだから、人工知能の方も両者を区別することができる。
GoogleやAmazonは検索エンジンや広告表示、おすすめ商品の表示の改良に機械学習を導入している。ということは大量のデータを必要とする。私個人の検索要求を正確に理解するために、私のすべての検索要求の履歴と、協調フィルタリングにおいて何らかの意味で私と「似ている」と判断された別の利用者の検索要求のデータ、そして世界中の厖大な数のネット利用者の検索履歴のデータを参考にして、私に特化した検索結果を表示する。
少数のデータから正しい答えを導き出す方法を、人工知能たちはまだ知らない。*1
*1:アニメ「あの日見た花の名前を僕達はまだ知らない。」(通称「あの花」)のもじり
X=746
1から始まって、その次に2がきて3がきて、数はどんどん増え続ける。今ではもう1000をゆうに超えてしまったことだろう。そしてこれから先も、この数はどんどん増え続ける。増えるスピードはゆるやかになっていくかもしれないが、減ることはなく、増え続ける。そして一つとして、同じ数はない。
そんな中で、もしも746が好きになったとしたら、たとえ他のすべての数もそれぞれにユニーク(もちろん「一意」の意味で)であるとしても、746の代わりを見つけることなどできはしない。746はどこまでいっても746なのであって、745や747とは決定的に異なる数である。そして746から拒絶され、746と違う数を求めて846や155などを検討したところで、どうすることもできない。かけがえがないというのはそういうことなんだろう。
数字で人間の個性を考えるなど言語道断だという考え方の人もいるかもしれない。ナイーブなロマンチシズムや魔術主義的思考様式に拘泥するならそれでもいいだろう。しかし数字で考えた方がわかりやすくなることも多い。それは彼らが思っているよりもずっと多い。
毎週毎週、日曜になると決まった喫茶店で746がやってこないかと待ち続ける。もちろん746はやってこない。これから先も、やってこないだろう。そうこうするうちに、私の「出会った人々カウンター」の数字はどんどん増え続ける。いずれ2000を超える日がやってくるのかもしれない。それでも私は、100人中99人が「それはただのストーカーだよ」と判定するであろうような執着をもち続けたまま、今でも746にこだわり続けている。
豆乳シフォンケーキを食べ終え、コーヒーをもうすぐ飲み干してしまう。キーボードの上を右へ左へと動き続ける私の指は、近頃どこかぎこちなくなっている。心にためらいがあるせいなのだろうか。いちいちタイピングする文字列について意識しなければ、タイプミスも減るし、スピードも早くなるのに、私は一体何を意識しているのだろう。何にこだわっているのだろう。Xは746だけとは限らないのに。
もう店を出なければならない時間だ。