ランキングと記憶と銀行について
私は時々、順序がつけられる前のウェブというものがどんなものだろうと考える。莫大な情報がなんの秩序(order / pattern)も持たずに散乱している広野のようなウェブ。検索エンジンが、ニュースキュレーションアプリが、或いはSNSが、私個人に最適化したランク付けをする前の、雑然としたページの大群、あるいはジャングルを自分で探検してみたくなるのだ。そのときの「探検」というのは英語で言えばsearchというよりもexploreの方が近いかもしれない。私はInternet Explorerは全く使わないが。
ウェブ上で目にするページの多くは順序がつけられた後のものだ。情報が多すぎるのだからこれは当然といえば当然かもしれない。探索するには情報が多すぎるために、検索エンジンといえば「ページのランクづけをするもの」ということにもなる。
「ネットサーフィン」という言葉がある。最近はあまり使われなくなった言葉だ。それは裏を返せば、ネットサーフィンという行為を支えるテクノロジーが、生活の中に浸透していって、多くの人々が、呼吸をするのと変わらない感覚でネットサーフィンを行うようになったことの裏返しなのだろう。「私は今まさに呼吸をしている」とわざわざ口にする人間はいない。
さて、サーフィンをするためには、波にうまく乗らなければならない。それも自分のすぐ近くの波に。遠いところにある波に乗ることはできないのだ。乗るべき波を見つけることを実現しているのが検索エンジンだとするならば、もしもそれなしでウェブの海へ出れば、私はウェブに飲み込まれてしまうだけかもしれない。波には近いものも遠いものもなく、いろいろな方向の波が混じり合い、どの波に乗るべきか、どういう風にすれば波に乗ることができるのかわからずに、ただただサーフボードとともに海にのまれるだけになってしまうかもしれない。
ネットでExploreするということ
ところで、そもそも私はウェブで「サーフィン」をしたいのだろうか。ウェブ上でできることというのは、サーフィンだけなのだろうか。なるほどインターネットは情報の海であって、その中で移動するのであれば「サーフィン」という言葉で表現するのが適当かもしれない。しかし、そもそもネットという空間を喩えるのに、「海」しかないのだろうか。海以外の、そしてサーフィン以外のいい比喩はないのだろうか。冒頭では"surf"の代わりに "explore" という言葉を使ってみた。
Internet Explorerは、かなり初期からGoogleを使うことによってexploreする人が多かったから、"Explorer" のようで実態は "Searcher" になっているといえる。それでは言葉の本来の意味での "Internet Explorer" はどこかにあるのだろうか。ネットで何かを探すときには、当然のように検索エンジンが使われるようになり、今やその大半がGoogleによって行なわれている状況では、Searcherばかりになっているのかもしれない。何かを知ろうとして検索ボックスに調べたい単語を入力するとき、私たちは当然のようにページのランク付けをGoogleに依頼することになる。
検索エンジンは図書館の「司書」(librarian)を参考にして、検索者が最も欲しがる情報を的確に探し出すことを目的として設計された。それは今も基本的には変わらない。検索エンジンの後でSNSが登場し、こちらは利用者の人脈を広げるだけでなく、その人脈を使って欲しい情報を探し出すという方向でも発展してきた。
ウェブというのは「蜘蛛の巣」であるから、検索エンジンとSNSでは後者の方がウェブと相性がいいという見方もできるように思う。情報の網(ウェブ)を、人間の網(ソーシャルネットワーク)を使って探し出すわけだ。今でも、何か知りたいことがある場合、検索エンジンを使うよりも「しかるべき人」に相談した方が、自分の欲しい情報を探し当てられることが多い。例えば私はロードバイクであちこちを走り回るが、見知らぬ土地へやってきたとき、Googleマップを使って経路を考えるよりも、その土地の住人に道を聞く方が、具体的な経路をイメージしやすかったりする。
ExploreとMemory
先日は割と分量のある文章で、グラフとランク付けの対応を中心にして検索エンジンの意味というものを考えた。SearchではなくExploreを行うためには、ネットを使うにあたってすっかり浸透しきっている「ランキング」というものから一度離れなければならない。
plousia-philodoxee.hatenablog.com
グラフをランク付けのリストに変換したりするのは、人間の記憶(memory)のしくみと関係があると私は思う。ここからは、記憶と言っても「長期記憶」に限定して話を進めていく。完全記憶を持つ人間は、自分の経験した出来事や見聞きしたことなどを何ひとつ忘れることができず、苦しむことになる。記憶というと、「覚えること」の方と結びつけて理解されることが多いが、これでは片手落ちであって、忘れることの方も同様に重要であると考えなければならない。何を覚え、何を忘れるかという選択によって記憶が成立しているというのが、少なくとも生物にとっての記憶の意味ということになるだろう。覚えることと忘れることは記憶という一枚のコインの裏表をなしている。
ランク付けのリストというのは、いわば人間の記憶の「代わり」なのではないだろうか。多くの人間が検索結果の1ページ目しか参照しないのは、多くの人間にとっては、思い出せる情報の量が検索結果1ページ分と対応するほどの量であるということなのではないか。私にはそんな風に思える。2ページ目以降はほとんど参照されなくても、存在していることがわかっていると、それらも自分の記憶と地続きであるかのように錯覚してしまわないだろうか。本当はそんなことは全くないにもかかわらず。
検索エンジンでは、たとえ私たちが見ないとしても、200位と201位のランキングが行われている。その二つのページのランク付けは、私たちの多くにとって意味をなさない。それは私たちがものを考えるときに思い出されないでいる事柄どうしの順序を問題にしている。
プラトンの『パイドロス』の中で、ソクラテスは彼の知人パイドロスと木陰で始終語り合う。対話の中で、人間が文字(書き言葉)を使って考えを記録しておけるようになったことによって、記憶力が衰え、ひいては思考力が衰えてバカになってしまうのではないかという懸念を示す場面がある。これは書き言葉に対する話し言葉の優位という文脈で論じられることもあるが、ここではこれとは別の文脈、つまり検索エンジンとの関係から考えてみたい。検索エンジンが、基本的には文字によって記述されたページの解析によって成立しているのは、パイドロスにおけるソクラテスの弁の意味では、人間の記憶と逆行する皮肉のようでもある。こうして「ネット検索は我々をバカにする」だとか、「ネット検索をする者はバカ」*1といった議論が生まれることにもなる。あるいは「記憶の外部化」という形で論じられることもある。
「長期記憶」に絞って話を進めてきたが、人間の記憶には短期記憶もある。人間がものを考えるとき、時間が経ってもいつでも思い出せる記憶(長期記憶)だけに基づいて考えを展開していくわけではなく、一時的に記憶している事柄も使って考えることはできる。ネットで何かを検索する時にも、この一時記憶に頼ったりする。一時的な保管庫に新しい情報を蓄えていって、それらと長期保管庫の情報を組み合わせて思考を展開しているというのが人間にとっての日常の思考の実態なのではないだろうか。
記憶を蓄えておく場所を指して「保管庫」と表現したが、これは「預金口座」に喩えることもできる。多くの人は、実際にはどんな金額でも預けることができるとしても、一定量の金額しか口座には預けない。もちろんそれはその預金額に比例する所得を稼ぐ人が多いからであって、人々がもっと多くの金額を稼ぐようになれば、それに応じて平均的な預金額も増えることになるだろう。しかし比例定数は増加しない。所得の3割を貯金する人は、稼ぐ金額が増えても貯金する割合は3割のままだろうと思われる。
教養とExplore
すぐに引き出して使うことのできる知識を「教養」と呼んだりすることもある。単に「知っている」だけの状態では、いつでも引き出して使いこなすことができる状態とは違い、それでは教養があるとは言えない、と。教養というのは本をたくさん読めば身につくというものでもない。それは言い換えれば、情報量を増やしても教養が身につく保証はなく、1冊1冊の本を丁寧に読むことによって、それほど多くの本を読んだわけではなくても、ちゃんと「教養」と呼べるものを身につけている人もいる。教養は本の読み方に依存して決まる。教養にもとづいてものを考えられるようになるためには、ある程度の集中力が必要になる。一定の範囲に限定して、その中だけで活字を追っていく。そして同時に、自分の頭をはたらかせて考え続けることで、初めて教養が身につく。そしてこれは、記憶と結びつけて考えるならば、長期記憶の領域の情報だといえる。一時的に吸収して利用するものを教養とは呼ばない。文字どおり、その人の血となり肉となっていなければならないのが教養である。
それでは、人間の持つ記憶と、ランキングが「資源の有限性」を媒介にして結びついているのだとしたら、ランキングから距離を取るのはそう簡単ではない。しかし、預金口座の比喩や教養について言及した箇所で述べたように、人間は長期記憶だけでものを考えているわけではなく、一時的に記憶した情報を使ってものを考えることもできる。ネットで検索をすればするほど、私たちは長期記憶をおろそかにするようになる。長期記憶をおろそかにするということは、その領域で醸成される教養にもとづいてものを考えることをおろそかにすることにもつながる。ネットがどんどん普及すればするほど、巷の書店では「教養本」があふれかえるようになっているのは、無関係ではない。ネットを使っていても教養は身に付かず、したがって体系的にものを考える術が身に付かないために、教養を身につける必要性は高まるのだ。
人々はどこかから引き出してきたお金を、まるで自分のお金ででもあるかのように扱い、預金口座に預けられている金額は一向に増えない。ネットを使うということがそういうことにしかならないのだとしたら、これほど情報が溢れかえっているというのに、なんという大いなるムダであることだろうかとすら思う。預金口座の残高を増やし、そこに作り上げられていく教養の樹を豊かにしなければ、たくさんの情報を簡単に集められても一向にものを考えられるようにはならないだろう。
*1:
即座に思いつく文献をあげると次のようなものがある。もっとも、この本のどちらも直観的に「ハズレ」のような気がして、私は読んでいない。私個人にとっては「筋の悪い議論」としか思えなくとも、ある程度は世間の中で話題になっているテーマではあるらしいので一応取り上げた。
")

主観的なランキングと客観的なランキング
Googleは当初、厖大なウェブページの客観的なランキングを行っていた。誰が見ても同じページは同じ順位にあって、新しいページが加わればランキングは更新されるが、それはランキングを見る人間とは独立に生成されるものだった。やがてランキングは「パソナライゼーション」という言葉で表現されるように「検索する個人」をランキングと結びつけるようになった。客観的なランキングから主観的なランキングへ、みんなにとってのランキングから私にとってのランキングへ変わった。今もランキングの「主観化」は続いている。
私は普段、ほとんど音楽を聴かない。だから音楽のジャンルや最近はやりの音楽などはちっともわからない。そんな私が、ネット上でたまたま見つけた音楽にハマるということがたまにある。いや、私が新しい楽曲を見つける時はいつも、私とは別の誰かのフィルターを通している。
ランキングというのは、私にとってのランキングであるよりも、他者にとってのランキングを参照する方が、面白いということなのではないか。しかし、それならば一体誰のランキングを参照すればいいというのか。私ならばここに一人しかいないけれど、他者となると厖大な数になってしまう。「信頼できる他者」という表現がすぐに浮かんでくるが、では信頼できるかどうかをどうやって判別するのか。たとえばこのはてなの世界は、ある程度のリテラシーを持つ人々が集まっていると当初からみなされているようなところがあって、それはアメーバブログに集まる人々とはタイプ的に異なる。どちらを参考にするかは個人によって異なる。
しかし、私が参考にしているのは他者にとっての主観的なランキングなのだろうか。他者は自分なりのランク付けを何らかの方法で実行し、それをウェブ上に公開し、それを利用することによって、セレンディピティー的な出会いがもたらされ、私はハッピー…という筋書きが正しいのだろうか。
Googleで検索するよりも、はてなで検索する方が面白いページに簡単に出会うことができるので、最近はもっぱらはてなでの検索を行っている。もっともはてなの検索はPowered by Googleなのであるが。そして今日も、大崎駅の近くのスターバックスにて、「検索エンジン 数理」といったキーワードで検索していると思わぬ形でこんな記事を発見した。
検索エンジンは、線形代数に支えられているという見方もできるが、グラフ理論に支えられているという見方もできる。そして線形代数とグラフ理論の間には密接なつながりがある。上記のキーワードで検索したのだからグラフ理論について扱ったページがヒットしたのもうなずけるが、なんとこのページで扱われている内容のほとんどはアブナー・グライフの『比較歴史制度分析』である。 ある情報が信頼に足るものであるかをどうやって判断するかということについて、人間はどのような「しくみづくり」をしてきたのかということを簡潔にまとめてあって、とても面白かった。
")
- 作者: アブナー・グライフ,神取道宏,岡崎哲二
- 出版社/メーカー: エヌティティ出版
- 発売日: 2009/12/09
- メディア: 単行本(ソフトカバー)
- 購入: 3人 クリック: 270回
- この商品を含むブログ (22件) を見る
Amazonで探すと、もはや中古でしか手に入らないらしい。新品にこだわる私としては残念であるが、とりあえず書店で探してみようと思う。
さて本題に戻ると、このページははてなの検索ではかなり下位の方にランキングされていた。「SEO対策バッチリ!」だとか「ちゃんと記事の最上部にいい感じの画像を貼って…」だとかをしない、内容だけで成り立っているページだから無理もないかもしれない。はてなで面白そうなページを探すとき、私は検索結果の10ページ目まで見ることにしている。ここまでくると、もはやランキングには意味はない。「私にとって面白いかどうか」ということとランキングは全く別次元のように考えているからだ。
もっとも、はてなの場合、ランキングはどれほど厳密に行われているのかはわからない。単に検索キーワードが含まれるページを表示しているだけかもしれないと思わないでもない。
私にとって、面白いページはランキングとは関係なく決まっている。それならばランキングになんの意味があるというのか。
どうやって「それ」を見つけ出せばよいか。どうやって "This is it !!" を実現するのか。ランキングが客観的なものから主観的なものへ変化しても、依然としてそれは「ランキング」であることに変わりはない。「検索=ランキング」パラダイムは揺るぎないということか。
面白いページを見つけたいとき、ランキング以外の方法でそれを実現することはできないものか…。最近はこの問題をずうっと考え続けている。なかなかすっきりした解にたどり着かないのは、一つには私がこの問題を何らかの形で定式化できていないことが原因だろう。問題を適切な形で定式化するためにはそれなりの専門知識と技量が必要とされるが、そのどちらもまだ私は十分に持ち合わせていないということだと思う。
路線図:駅:街→私
(東京の路線図。なんとまあ複雑なことよ。)
はじめに言っておくと、この記事は路線図と街の関係について書いているようで、実はそうではない。テーマが何であるかは読み手の方々の想像にお任せする。そんなにもったいぶるほどわかりにくい比喩でもないとは思いつつ…。
人気の駅と人気の街
路線図を観察していると、たくさんの利用者がいる駅にはたくさんの路線が通っていて、その周辺部は栄えていることがわかる。路線図は数学的には「グラフ」(無向グラフ)として扱うことができるから、その構造を分析する事によって、特定のノードとしての「駅」が、すべての駅の中で何番目に優れているかといったランキングを作ることができる。
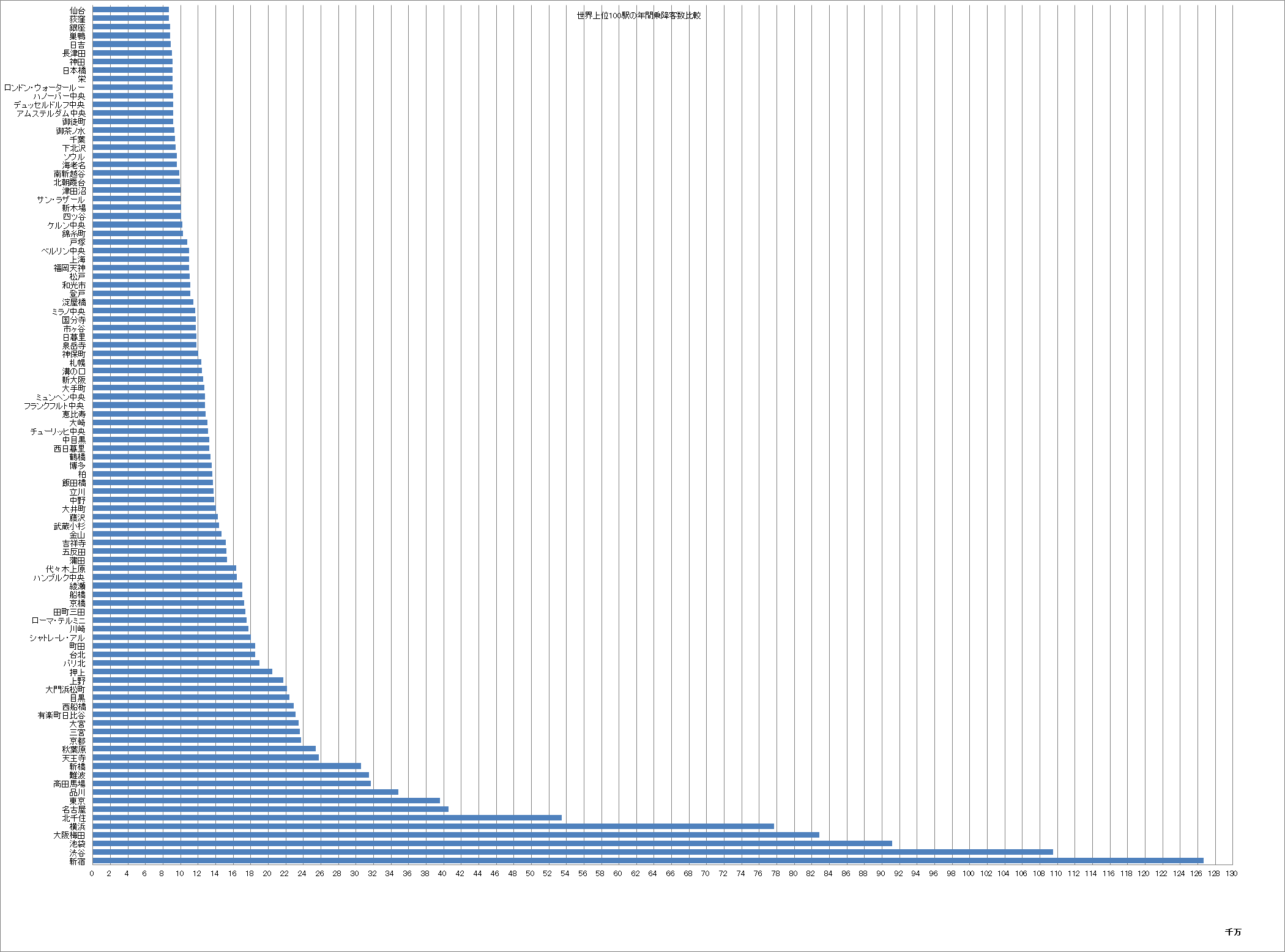
(世界上位100駅の年間乗降客数ランキング。なんとすべて日本の駅。
出典:世界上位100駅の年間乗降客数比較、日本だらけでワロタwwwwwwww : はちま起稿)
ここで、「優れているとされる駅の周辺は、街として繁栄している」という正の相関関係があるならば、駅のランキングを行うことによって、私たちは間接的に街のランキングを行っていることにもなる。「優れている」ということには何らかの価値判断が入るけれども、特定の価値観を反映したランク付けでは客観的とはいえないので、なるべく恣意性の入り込む余地のない形でランキングを行う必要がある。
そこで考えられるのは、冒頭に述べたように、多くの駅とつながっている駅のランクを上位にもってくるという方法だ。この方法を使えば、特定の誰かが大量の「サクラ」として、「あの駅いいよ!」と声高に主張していたとしても、そういう特定の個人の評価だけに左右されずに、多くの人間の評価の最大公約数をとって、より公平なランク付けを行うことが可能になる。
ここで、「自分はどこに住むべきか」を考えている人物Aと人物Bがいたとする。彼らはこの「駅ランキング」を参考にして、その駅が最寄駅であるような場所に住もうと考える。Aにとっての「いい街」とBにとっての「いい街」は、上のようなランク付けの方法では同じになるだろう。しかし個人から見れば、最大公約数的な「いい街」と自分の考える「いい街」とは必ずしも一致しないという問題に直面する。そこで、ランキングを行う企業Gは、ランキングを利用する人間の個性をランキングの結果に反映するようなランク付け方法の改良を行う。ただし、グラフ構造からランク付けを生成するという前提は崩さずに。
点と線のかたまり、或いはリスト
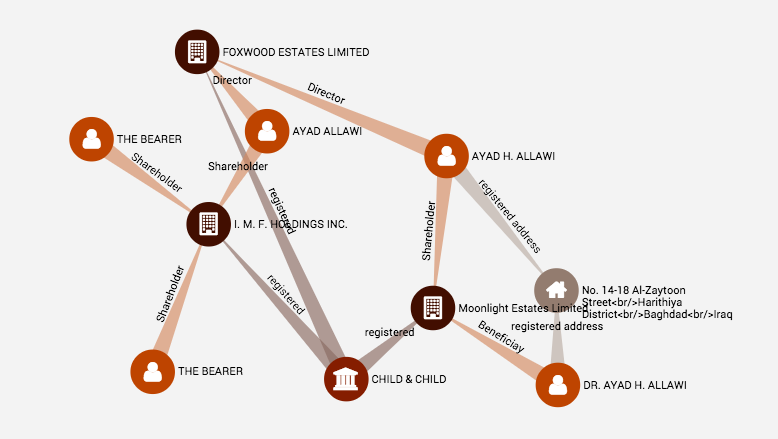
(最近話題のパナマ文書に関する、株主や取引関係を示したグラフ。
出典:パナマ文書の取引や株主の情報がグラフ構造として公開されてるらしい - データの境界)
何かをランク付けしたければ、それについてのグラフがあればよい。そのグラフの構造を分析すれば、ある特定のノードがグラフ全体の中で何位にランクインしているかがわかる。点と線のかたまりは、一定の手順で処理されたのち、リストに変わる。
点と線のかたまりも、リストも、その背景には「競争」(competition)がある。点と線のかたまりにおいては、かたまりの中でたくさんの線が延びている点が優秀ということになるし、リストにおいては、上にきているものほど優秀ということになる。競争で勝ったものこそ、より多くの人に知られるべきであると。
競争というメカニズムは、よりよいもの、正しいものを選び出すアルゴリズムになっていて、より長い時間経過の末に生き残ったものは価値が高いとされる。逆に淘汰されたものは、知られるべきものではないとされ、点と線のかたまりでは周縁に位置付けられ、リストにおいては下に回される。リストは、やるべきこと(ここには「買うべき食材」だとか、「手をつけるべきタスク」だとか、いろいろなものが当てはまる)を考えるときに最もよく利用される。

(一般的(?)な買い物メモ。
出典:たぶん誰もやってない「買い物メモ」の書き方 - mind and write)
買うべき食材をリストにまとめるとき、私たちは当然のように、今すぐ必要な食材だけをリストアップする。すぐに必要のない食材をわざわざリストに書く人はほとんどいないだろう。スーパーに行ったところで今すぐは必要でない食材を買ったりはしないからだ。これはまるで、検索結果の1ページ目だけを見るという行為のようだ。いや、「AはまるでBのようだ」と言うよりも「AはBと同型である」と言う方が正確だろうか。どちらも、私たち人間の「注意力」という資源に限りがあることに起因する現象だ。そして言葉の定義上、全てに対して注意を払うことはできない。一部に対して払うからこそ、注意は注意として十全に機能する。
ランキング→グラフ
ある特定の構造をもつグラフを、一定の手順で処理することによってランキングという別の表現に変換することができるのだとしたら、その逆の処理は可能なのだろうか。つまりランキングを与えられれば、そこから特定の構造をもつグラフを生成することはできるだろうか。これはおそらくできる。それでは先ほど登場した買い物リストは、グラフに変換することができることになる。リストの上位にきている食材ほど、よく使われる食材という事になるだろうから、ある個人の買い物リストを長期にわたって収集すれば、それを可視化したグラフから料理の傾向がある程度明らかになるだろう。これは街と路線図の間にも同様に当てはまることだと思われる。つまり、ひとたび街のランキングを作ってしまえば、そこからまずは駅のランキングを生成した上で、上位の駅がたくさんの駅とのつながりを持つようなグラフを生成することができるだろう。なるほどこのように考えてみると、グラフとランキングの結びつきは強固であって、そこには切っても切れない「腐れ縁」や「運命の赤い糸」のようなものすら感じさせる。
XとYには一対一の関係が成り立つ時、その「対応のさせ方」のルールさえわかっていれば、どちらか一方から他方を復元することは難しくない。グラフからランキングを、或いは逆にランキングからグラフを生成することができる。まるでDNAの二重らせん構造のようだ。ただしそのルールは、人物Aも人物Bも詳しくは知らず、ただベターな解判定の仕組みとしての「競争」に対する素朴な信頼が、ランク付けの大規模かつ継続的な利用を支えている。
注意を向ける範囲には限りがあって、競争というものがその範囲をうまく決めてくれるのだとしたら、人間が、競争というメカニズムに沿って、自分の注意を向けるべき対象をうまく限定することには一定の合理性があるように思われる。競争は歪んでいるかもしれないし、勝者総取り(Winner-Take-All)という固定化が起こりやすいとしても、競争に対する信頼はそう簡単には揺るがない。もちろん一部には競争というメカニズムに対して懐疑的な人間もいて、そういう人間たちは自分の目で下位の駅の調査も行う。ランキングの主導権を、「あちら側」から「こちら側」に持ってこようとする。それはまるで、食べログには載っていない隠れた名店を探そうとするグルメたちの行為のようでもある。いや、同型である。
競争を利用したランク付け
よりよい解を判定するために、競争というメカニズムはいたるところで利用されている。いや、「利用されている」などと書くと、人々が意識的に競争という方法を選択したかのように響くけれど、実際には自然発生的に競争状態が生じることがほとんどである。
私自身、学部時代には経済学を学んでいたから、市場における競争のメカニズムによって、いかに効率良く資源(商品も含む)が配分されるのかということについて学んだ。効率的な資源配分が競争というメカニズムによって達成されるためにはどんな条件が必要であるかということは経済学の基本的な問題であって、「その条件というのが現実には当てはまらず、したがって経済学など所詮は机上の空論に過ぎない」という論調も何度となく目にしてきた。情報は完備(complete)でも対称(synmetric)でもないし、市場は完全競争(perfect competition)ではないではないか、と。
それでは経済という領域において、よりよい商品が市場に出回るようにするためには、競争以外に何かいいメカニズムはあるのだろうか。政府の介入によって市場の不完全性を補完するという立場がひとつある。けれども実際には介入が失敗することも少なくなく、人々は失敗のたびに政府による介入に懐疑的な姿勢を強める。政府に任せようとする考えが生じるのは、調整を行う力を持っている主体が政府であるからだということだと思われるが、本当に政府だけだろうか。合理的な調整を行う力があるならば、それを実行する主体が政府である必要性は消えてしまう。「その時、政府は…」という政治学の問題はここでの議論からそれるので考えないことにしよう。
ランキングの方法が完全でない場合、それをうまく調整できるやつが調整すればいいじゃんという考え方を採用するとして、「調整」というのは順位の調整でなく、結果の調整である。もちろん順位を調整するという考え方もあるが、それは「結果の調整」という問題の側から見れば、副次的な問題にすぎない。駅と街の問題の場合、複数の駅を一つにまとめることは難しいけれども、もしも調整にかかる摩擦が少ないならば、思い切って複数の駅を一つにまとめてしまった方がよりよい結果になる場合だってあるだろう。私は普段、通勤に井の頭線を利用しているが、駅と駅の間隔は他の路線よりも短く、思い切って駅の数を減らした方が利用者にとっても都合がいいのではないかと思う時がある。もちろん現実には摩擦が大きすぎてこれは不可能だろう。しかし可能なのだとしたらやるべきだという風に考えてみることにはそれなりの意義がある。少なくとも、この記事の冒頭に述べたように、それが駅と街の関係の問題のようでいてそうではないのだとしたら。
この記事のテーマに関係する、これまでの自分の問題意識を表現した過去記事たちを、ここでまとめて添付しておくことにしよう。備忘録として。
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
plousia-philodoxee.hatenablog.com
ゲームとメタゲーム
たいていのゲームには、「そのゲームに勝つ(負ける)ことによって」という形で勝敗が決まる「メタゲーム」が存在すると私は思う。親が自分の子どもとの勝負(何かもっと具体的な例を挙げるべきなのだが、あいにく思い浮かばない。各自で適当なものを当てはめてみてほしい)でわざと負けてやるとき、それは親が「親としての役割を果たす」というメタゲームでは勝ったことになるし、逆に親が子供を完膚なきまでに負かしたとしても、それで子どもが自信を失ってしまったりなどしたら、それはもうメタゲームでは親の負けだ。この場合はゲームでの勝敗とメタゲームでの勝敗が逆転しているが、両者の勝敗が一致する場合もある。子どもがはまっているテレビゲームで親子が勝負する場合、親がテレビゲームに勝てば、子どもからの尊敬や信頼を勝ち取ることによって、メタゲームでも親の勝利と考えることができる。
このゲームとメタゲームの関係を表す文句に、「勝負に勝って試合に負ける」というのがある。勝負がメタゲームに対応し、試合がゲームに対応すると考えればよい。
頭のいい東大生が、なぜか世間からの評価は低かったりするのは、ゲームには圧倒的な勝利を収めていても、メタゲームの方では負けてしまっている場合が少なくないということの表れなのかもしれない。こんなことを書くと語弊があるかもしれないが、どうもそういうことなのではないかと思う。例外となる人々もいるにはいるが他の大学の場合に比べると割合は低いように思う。ゲームに没頭しているうちに、実は同時進行しているメタゲームの存在に気がつかないままゲームが終わってしまったということなのではないか。
もう一つ、「あの人悪い人ではないんだけどね…」と他人から言われている人や、「あの人優しいんだけどね…」と言われている人なども、「人格者ゲーム」では勝ちかもしれないが、それと同時進行する「恋愛ゲーム」という名のメタゲームでは負けてしまっているのかもしれない。人格的に優れていれば、恋愛がうまくいくわけではないけれど、それでも人格が優れていることにこだわってしまったりする「優等生タイプ」の人などは、大変だろうなと思ったりする。私にもそういうところはある。こういう場合に注意しなければならないのは、人格者ゲームで勝つこと=恋愛ゲームでの勝利という風に考えてしまったり、実は人格者ゲームで戦っていることになっているのに、自分では「これは恋愛ゲームだ」と勘違いしてしまっているような場合だ。ゲームとメタゲームを混同してしまうと、冒頭で述べたように両者の勝敗が逆立する場合はメタゲームの方で負けてしまう。もちろん、人格者であることによって、恋愛もうまくいく人もいるだろう。ただし、それはサッカーや将棋やポーカーのようなゲームのように、勝ち負けが明確に判定可能というわけではない。メタゲームの勝敗は曖昧だ。
ゲーム理論では、ゲームに勝つための有効な戦略が説かれている。それはメタゲームの戦略を考える際にも役に立つことはあるだろう。しかし、ゲームとメタゲームの勝敗の関係は自明でないから、しっぺ返し戦略や裏切り戦略などを活用しても、メタゲームでは負けてしまうということがありうる。
私は今、どんなゲーム、どんなメタゲームのフィールドの上にいるのか、そしてちゃんと戦えているのか、とふとそんなことを思った。
【追記】
この記事をFacebookに投稿したら、大学時代の友人からコメントをもらった。それについて少し説明が必要だと思われるので、ここに追記しておこうと思う。メタゲームの勝敗というのは、それを評価する人間の主観に左右されるところがあるということだ。ゲームの方はルールが厳密に決定されていて、それにしたがって勝敗が決まるが、メタゲームの方はルールが厳密でない場合が多く、何をもって勝ち(負け)と判断するのかが明らかでないことが多い。だからあるゲームの勝者が、Aにとってはメタゲームの勝者と移り、Bにとっては敗者と映るというようなことはままあることだ。分かりやすい例は起業家の評価であろう。ビジネスで大きく成功したのであれば、ビジネスというゲームにおいては勝者と考えて問題ないだろうが、それが「ビジネスの成功によってその人はどういう人間であると思われるか」という形のメタゲームにおける評価となると、ある者は彼を資本主義システムにおける勝者にとどまらず、人生における勝者と見なして羨み、ある者は彼を資本主義システムにおける拝金主義者と見なして人生においては成功しているとは言い難いとみなすだろう。このときメタゲームにおける勝敗は、個々人によって評価が分かれることになる。だから、もしも自分がゲームのプレイヤーの立場である場合には、問題はメタゲームの勝敗を評価する人間の「ものさし」を知っておくことだろう。
サイコロが人とAIを振り分ける
サイコロの各目の出る確率を考えるとき、人間は何度も繰り返しサイコロを振らなくても、極端な話、一度もサイコロを振らなくても、それぞれの目が出る確率が6分の1であることを見抜くことができる。これを「直観」と呼んでいる人も多い。少数のデータから答えを見つけ出すことと言い換えてもいいだろう。以前、統計に基づく処理を行う自然言語処理では、大規模な集団のマクロな傾向は分析することができても、個別の人間の特性を推定することは難しいということについて触れたことがあった。
plousia-philodoxee.hatenablog.com
これに対して、もしも人工知能が同じ問題に対処するとしたら、とにかくサイコロを実際に振ってみて出た目のデータを処理して統計的に6分の1という確率を弾き出す。だからもしも一度もサイコロを振らなければ、或いは少ない回数のデータしかなければ、人工知能は統計が使えないから、サイコロの出る目の確率を正しく答えることができない。この意味では人工知能には直観がない。
ただし、確率を計算するための大量の結果だけがわかっている場合には、人間が計算しても人工知能が計算しても大した違いはない。人間が人工知能と同じ確率をちゃんと計算できたとしても、どうしてその確率になるのかという「メカニズム」の方はわからないからだ。サイコロの場合であれば、サイコロの面の数は6面あって、それぞれの面が上にくる確率は互いに等しいとすぐに見抜くことができたから、一度そのメカニズムさえわかれば答えを出すのは容易かった。
すると、直観というのはメカニズムを見抜くことと何か関係があるのかもしれない。ここで「関係がある」という断言を避けているのは、少なくとも私個人の場合、何かが直観的にわかったという場合、メカニズムがわかっている場合と、わかっていないけれどもなぜか答えはわかるという場合の両方があるように思えるからだ。IQテストのようなパターン認識系の問題の場合なら、メカニズムがわからなければ原理的に解けないようになっているから、直観とメカニズムの認識は不可分に結びついている。しかし、例えば街中を歩いていて、「なんとなくこっちに行った方が近道だという感じがする」というような場合には、メカニズムはよくわからないまま直観だけが生まれている。
「ディープラーニング」(深層学習)の研究が進み、人工知能が大量のデータから何らかの「特徴量」を取り出すことができるようになった。それは人間がこれまで「意味」と呼んでいたものと同じなのではないかと考える人もいる。サイコロの例でいえば、人工知能もサイコロが6面あるということを大量のデータから理解することができるようになったという風にいえる。しかしそのためには「大量のデータ」が必要なことは変わらない。量を質に変えるためには、そこが前提条件だ。だから逆に、少数のデータから特徴を取り出すことは相変わらずできないままだ。
いまここに、十分な量のデータがそろっていれば、人工知能の方が早く正確に答えを出すことができるかもしれない。しかしデータの量が少ししかなければ、人工知能は早く間違った答えを出す可能性が高い。データの偏りが原因である可能性もあるが、何よりも少量のデータからメカニズムをつかむことが、機械学習では不可能であるからだ。たとえばここに普通の6面サイコロと、8面サイコロの二つがあり、それぞれ10回ずつ振ってみたとする。どちらも1〜6の目しかでなかったとしたら、人工知能は6面サイコロと8面サイコロを区別することができない。人間ならば、一目見ればたちどころに両者を区別できる。これが10回でなく、100回とか1000回のデータであれば、8面サイコロの方で7や8の目が出るはずだから、人工知能の方も両者を区別することができる。
GoogleやAmazonは検索エンジンや広告表示、おすすめ商品の表示の改良に機械学習を導入している。ということは大量のデータを必要とする。私個人の検索要求を正確に理解するために、私のすべての検索要求の履歴と、協調フィルタリングにおいて何らかの意味で私と「似ている」と判断された別の利用者の検索要求のデータ、そして世界中の厖大な数のネット利用者の検索履歴のデータを参考にして、私に特化した検索結果を表示する。
少数のデータから正しい答えを導き出す方法を、人工知能たちはまだ知らない。*1
*1:アニメ「あの日見た花の名前を僕達はまだ知らない。」(通称「あの花」)のもじり
X=746
1から始まって、その次に2がきて3がきて、数はどんどん増え続ける。今ではもう1000をゆうに超えてしまったことだろう。そしてこれから先も、この数はどんどん増え続ける。増えるスピードはゆるやかになっていくかもしれないが、減ることはなく、増え続ける。そして一つとして、同じ数はない。
そんな中で、もしも746が好きになったとしたら、たとえ他のすべての数もそれぞれにユニーク(もちろん「一意」の意味で)であるとしても、746の代わりを見つけることなどできはしない。746はどこまでいっても746なのであって、745や747とは決定的に異なる数である。そして746から拒絶され、746と違う数を求めて846や155などを検討したところで、どうすることもできない。かけがえがないというのはそういうことなんだろう。
数字で人間の個性を考えるなど言語道断だという考え方の人もいるかもしれない。ナイーブなロマンチシズムや魔術主義的思考様式に拘泥するならそれでもいいだろう。しかし数字で考えた方がわかりやすくなることも多い。それは彼らが思っているよりもずっと多い。
毎週毎週、日曜になると決まった喫茶店で746がやってこないかと待ち続ける。もちろん746はやってこない。これから先も、やってこないだろう。そうこうするうちに、私の「出会った人々カウンター」の数字はどんどん増え続ける。いずれ2000を超える日がやってくるのかもしれない。それでも私は、100人中99人が「それはただのストーカーだよ」と判定するであろうような執着をもち続けたまま、今でも746にこだわり続けている。
豆乳シフォンケーキを食べ終え、コーヒーをもうすぐ飲み干してしまう。キーボードの上を右へ左へと動き続ける私の指は、近頃どこかぎこちなくなっている。心にためらいがあるせいなのだろうか。いちいちタイピングする文字列について意識しなければ、タイプミスも減るし、スピードも早くなるのに、私は一体何を意識しているのだろう。何にこだわっているのだろう。Xは746だけとは限らないのに。
もう店を出なければならない時間だ。
玉石混交の単位
「ネット上の情報は玉石混淆だ」としばしば言われる。専門家も素人もネット上にいろいろなことを書き込むためにこういう言われ方をするようになる。インターネットが登場して以来、この「玉石混淆」という形容が使われるようになってからもうずいぶん経ち、その間もネット上の情報は増え続け、今でも情報は凄まじいスピードで増え続けている。そして今後も増え続けるだろう。
以前にどこかで読んだが、人間が発話で作る文(sentence)というのは、これまでに世界で使われたことのない文であることがほとんどであるそうだ。この情報のソースを確認しようとGoogleを使ってみたが、うまく調べることができなかった。これにはこの現象を形容する適当なラベル(そのほとんどは「名詞」(noun))が存在しないためだろう。
検索エンジンというのは基本的に「名詞」向けに偏って設計されていると私は思う。検索ボックスに何か単語を打ち込むとき、そのほとんどは名詞だろう。そして、検索者のほとんどが名詞ばかりで検索をかけるから、名詞に関する検索の質は高まっても、その他の品詞を使った検索要求に対する回答の質は向上しにくいという偏りが生まれる。この偏りは、Googleが意図して生みだしたものであるかどうかということとは関係ない。人間がただ検索を実行しているだけで自然と生まれてしまう類の偏りだ。だから却っていっそう厄介だと思う。
人間は物を考えたり表現したりするときに、名詞だけでなく、特に形容詞(明るい、美味い、キモいなど)や副詞(マジ、とても、早く、効率良くなど)をよく使うが、それらを検索語句として正確な検索を実現させることはまだまだ難しい。「おしゃれな服」と打ち込んだところで、検索結果で表示されるのは、自分が考える「おしゃれ」とは食い違った「おしゃれ」ということになるだろう。それはイーライ・パリサーが指摘する「パーソナライゼーション」が進もうと同じことだ。
話が逸れてしまったので元に戻そう。この「新しい文を作る」現象について、自分自身の今日一日を振り返ってみると、「おはよう」とか「ありがとう」とか「さようなら」というような定型表現を除いては、確かにほとんどの文はこれまでに自分が使ったことのない文であると感じる。これについて、「ひとつひとつがオリジナル」というキャッチコピーを与えてもいい。こういう意味では私は今日、特に意識もしないままに世界に対して新しい情報をいくつも提供したことになるわけだ。もっとも「情報」という言葉には注意が必要で、いま「情報が増え続けている」と書いたのは単にデータ量のことを指している。もう少し違った意味で情報という言葉を使うこともできる。
たとえばプラグマチックに考えるならば、それを手にした個人や集団に何らかの行動の変化をもたらすものを情報と定義することができる。例えば今日、どこかで誰かがが「太陽が東から出て西に沈む」という普遍の事実を自分のブログに書いたとして、それが誰かの行動に変化をもたらすとは限らないし、そういう情報は既にネット上に存在しているだろう。だからこれは「情報」とはいえない。
このように考えると、ネット上では情報はそれほど増えていない。毎日毎日、芸能人や著名人のブログ記事や大手新聞サイトの記事や、SNS上の個人の投稿など、次から次へと新しい文章が山のように投稿されているが、誰かの行動を本当に変えるような文章というのは少ないものだ。ライフハック系の記事などは、ニュースキュレーションアプリでどんどん出てくるが、私の行動に変化をもたらすものはそれほど多くはない。
さしあたってこの記事では、「情報」という言葉について、プラグマチックな意味での定義を採用して論を進めることにする。「玉石混淆」という表現が使われるとき、それはある特定のサイトの中の複数の文章に対してであったり、ネット全体に対して使われていることが多い。しかし考えてみると、玉石混淆という言葉は、ある一つの記事の中でいい部分と良くない部分があるという意味で使うこともできる。特にその文章が大部なものである場合には。
さてそれでは、玉石混淆という言葉をどの単位に対して使うかについて、上の二つに準えたケースを考えてみよう。
Case 1:ある二つの記事について、一方は良記事で他方は悪記事である場合
仮に良記事のURLをhttp://abc.com/article1822533(= URL X)とし、悪記事の方をhttp://xyz.jp/minorcats/104423(=URL Y)とする。こういう場合、検索エンジンは問題なく機能する。良記事のあるページ、つまりURL Xを上位に表示し、悪記事、つまりURL Yをなるべく下位に表示するようにランキングのアルゴリズムを調整すればいいという話だ。これは検索エンジンが当初からやっていることであって、特に珍しくもない。
Case 2: ある記事の文章の内部で、良い部分と悪い部分がある場合
この場合、いい部分も悪い部分も同一のURLに対応する文書として存在するために、既存の検索エンジンでは同一の単位として評価されることになる。同一のURLの内部で良い部分だけを切り取って上位に表示し、悪い部分は別にして下位に表示するというようなアルゴリズムは今のところ存在しない。少なくとも私はそういう検索エンジンを見たことがない。
それではこちらの意味で「玉石混淆」が使われている場合には、私たちはまだ、自分の頭で内容の良し悪しを判定しなければならず、そのためにはどうしても良いものと悪いものの両方をチェックするはめになる。情報が増え続ける毎日の中、限られた時間の中で、これを実行するのは中々難しい。
私たちは少なくとも名目的には民主主義を掲げる社会に暮らしている。だから社会で起こる様々な問題についてある程度の関心を持っているということが市民の義務のようなものとして求められる。もちろんこれには限界があって、私たちが議員を選出することによって、彼らに重要な議論や意思決定を代行してもらっているわけだが、どの議員を選ぶべきであるかという問題はどうしても残り、その問題に対処するときには、ある政治なり経済なりの問題について、自分なりの考えを持っていなければ、その問題について特定の政治家の判断が妥当であるかどうかということを正当に評価することはできない。
結局私たちは、代議制というシステムを採用していても、自分たち自身である程度公共の問題について考える必要性から解放されることはない。そしてこの問題について考えるにあたって、メディアは重要な役割を担い、そのメディアの中ではいろいろな人間が日々あれこれといろいろなことを書いている。それらのすべてに目を通すということは、専門家や評論家などを別にすれば実質的には不可能であるといってよい。大量の文書をうまくまとめて整理する人間が現れる。或いは最近ではそういうものをまとめるサービスも出てくる。しかしどれもしっくりこない。
「玉石混淆」という言葉の用法についての考察を通して、「公共の問題に対処する大衆の判断能力を担保するにはどうするべきか」という問題への対処法を見出したいと思う。それは別の言い方をするならば、「知りたいこと」と「知るべきこと」の線引きの問題でもある。
百貨店と検索エンジン
改めて考えてみると、百貨店と検索エンジンには共通する問題がある。そのことについさっきふと気がついた。百貨店は常に、限られた時間しか持たない利用者に、百貨店の中に並ぶ複数の店舗に足を運んでもらって、欲しいものをちゃんと入手してもらう仕組みを考えるという問題を抱えている。これは検索エンジンが抱える問題と同じだ。しかも問題に対する対処法まで似ている。どちらも「配置」を調整することによって、利用者の利便性を向上させようとするのだ。百貨店の場合は文字通り空間的な配置をうまく調整することによって、利用者が見て回りやすいようにする。そして検索エンジンの場合、ランク付けのアルゴリズムを改良し続けることによって、利用者が求める情報にたどり着くまでの時間を短縮するべく、表示するページの順番を決める。これはとても興味深い。
今日は渋谷にある東急百貨店で検索エンジンに関する専門書を購入した。『情報検索の基礎』と『検索エンジンはなぜ見つけるのか』の2冊である。それからアルバイト先の新人歓迎会に参加したのだが、集合場所には時間よりも30分ほど早く着いたので、近くのスタバでさっそく『検索エンジンはなぜ見つけるのか』の方の冒頭を何ページか読んで時間を潰した。百貨店で検索エンジンの本。意外なことにその二つには共通点があった。こういう発見があると妙にテンションが上がってしまう。

- 作者: Christopher D.Manning,Prabhakar Raghavan,Hinrich Schutze,岩野和生,黒川利明,濱田誠司,村上明子
- 出版社/メーカー: 共立出版
- 発売日: 2012/06/23
- メディア: 単行本
- 購入: 2人 クリック: 69回
- この商品を含むブログ (5件) を見る

SNSのある種のつまらなさについて
たまにFacebookやTwitterなどで、「〇〇について詳しい方いらっしゃったらぜひ教えてください!」という投稿を目にすることがある。
人望のある人間や信用のある人間、社交性のある人間、平たく言えば「リア充」とも言えるような人々なら、その投稿にたくさんのコメントがついたり、「自分は知らないけどこの人なら知ってると思う!」というような助けを得ることができる。
けれどもそうではない人間たちは、何のコメントももらえずに投稿はスルーされるだけ。私もまた、そちら側の人間だろうと思っている。だから惨めになるのが嫌で、SNS上にそういう相談に関する投稿はしないことにしている。
友達の数が1000人を超えるようなごく一部の人気者の人々にとっては、ソーシャルメディアはGoogle以上に利用価値のある情報サービスだと言えるだろう。皮肉を込めてそれに「絆って大切。」という形容を与えてもいい。
しかしここで考えが止まってしまっては、よくある「非リア充の鬱憤や僻み」に過ぎず、ありきたりすぎて詰まらない。それは上に書いたようなこと以上に詰まらない月並みさだ。だから視点を変えてみる。
改めて考えてみると、SNSを使って情報を集める場合に求められるスキルというのは、「適切な語句を知っているかどうか」といったことではなく、検索とは直接関係のないスキルばかりだ。つまり人当たりのよさや知名度、社会的地位、これまでについた「いいね!」の数などなど、どれもこれも「何かを調べる」ということとは直接関係のない要素ばかりなのに、それらが「調べる」という行為の結果を大きく左右してしまう。
そんなよくわからないスキルによって得られる情報に差が生まれるような仕組みは、私は好きではない。この感情の由来が、単にリア充な人々への僻みに過ぎないのだとしても、やはり好きではない。誰が使っても同じように機能するから「優れた仕組み」なのであって、一部の人間にしか使いこなせないようなツールは、まだまだ改善の余地があると考える。
Facebookを作ったマーク・ザッカーバーグは、今ではすっかり有名人だから、どんな話題であれ彼が何かを投稿すれば、大勢の人間からレスポンスが返ってくる。彼はすっかり「あちら側」の人間だ。しかしFacebookを作った当時の彼はどうだっただろう。どちらかといえば「あちら側」にはいない人間だったのではないだろうか。何か相談したいことがあっても、世渡りのうまい人間のようにうまく立ち回ることができず、自分の力だけで解決したり、運良く誰かの助けを得られることを祈るというような、おそらく世界中の大多数の人々と同じ側にいたのではないだろうか。彼は有能な人間だったから、自分の力だけでも大抵のことを解決することができたかもしれない。しかし有能な人間というのはごく一部だ。
ここで多少SNS側のことを気遣うようなことを言うとすれば、仮にごく一部の人間しか使いこなせないような仕組みだとしても、その人たちが何らかの利便性 を享受しているのなら生み出された価値があったということは言えると思う。インターネットは広大であって、たとえマス向けではなくかなり限定的なターゲット(「限定的なターゲット」とは何とも同語反復的である)が相手であってもマッチメイクが可能であるという特徴があることは、既にクリス・アンダーソンが『ロングテール』*1で指摘済みだ。
ただその一方で、SNSには人間関係スキルが問われるという点は、ソーシャルメディアという存在の本質を考えるとおそらくこれからも変わらないということも確かである。これが不確かであるように思えるなら、SNSに可能性を感じもしたのであろうけれど、おそらくこの点は今後も変わらないということは、明日の天気について気象庁が行っている予測と同じくらいの精度で確かであるようにしか思えない。だから「つまらない」のだ。SNSの普及によって促進された、人と人のつながり(ソーシャルグラフ)は、実際のところ思ったほどうまく活用されてはいない。もちろんソーシャルグラフを有効に活用している企業は少なくないだろう。しかしSNSの利用者の側はそうではない。もしも自分が「人気者」の側にいないならば。
*1:
")
ロングテール‐「売れない商品」を宝の山に変える新戦略 (ハヤカワ・ノンフィクション文庫)
- 作者: クリス・アンダーソン,Chris Anderson,篠森ゆりこ
- 出版社/メーカー: 早川書房
- 発売日: 2014/05/23
- メディア: 文庫
- この商品を含むブログ (3件) を見る
Wikipediaの記事の生成を自動化できるか
Wikipediaの記事にはいろいろな参考文献のリンク情報が載っている。それらは書籍であったり、特定のウェブサイトであったり、論文であったりする。ある項目について記事を書く場合に、どういう情報が必要であるか、どういう書籍のどの部分を使って文章を書けば読み手にとって理解しやすい文章になるかということは、今は人間の手によって行うのが標準的なのだろうが、どうも最近目にした情報によるとWikipediaの内側はごく一部の人間が編集権を占有しているらしく、他の人間が書いた記事の内容は彼らによって簡単に修正されてしまうような状況に陥っているらしい。
ちなみに記事はこちら。
これはある意味でとても残念な話で、多くの人間が利用している知識の確認サービスであるWikipediaの編集がかなり恣意性を含んだものであるということになる。もっとも編集というのはその定義上、中立ではありえない。マスメディアというと公平性や客観性、中立性が求められるという議論が今でもなされていることがあるが、実際にはそんなことは不可能で、どんなメディアであれ、メディア自体が何らかのバイアスを生んでしまうということは、メディア自体の中立性について懐疑的な目を向けたマクルーハンが、随分前に指摘している事実である。
私は最近の個人的な関心として、赤と青の絵の具から紫の絵の具を作るということを可能にする検索エンジンを作ることができないかということを考えているが、この問題を考えるときに参考になりそうだと思えるのが、Wikipediaである。
すでに以前の記事*1で指摘したように、現行の検索エンジンというのはどれも、やっていることの本質は「分類」と「ランク付け」であり、その単位はウェブページである。文章中の特定の段落や文など、ウェブページよりもさらに小さな単位でランク付け表示を行うことはできないし、ましてやウェブページよりも小さな単位の情報を組み合わせるということはやっていない。
さきほど何の前触れもなくあっさりと赤と青から紫を作るというようなことを書いたが、これは今の検索エンジンについての比喩である。つまりネット上に赤や青、黒、白、茶色、黄色、緑といった絵の具しかなく、検索者は紫の絵の具が欲しいという場合、現行の検索エンジンが何をするかといえば、紫との「関連度合い」(relevance)が高い絵の具、つまり赤と青の絵の具をランキングの上位に持ってきて差し出すということがせいぜいだ。せっかく赤と青の絵の具があっても、それを混ぜて紫の絵の具を作るということは、検索エンジンにはできないし、そもそもそういう風に設計されていない。
想像してみて欲しい、自分は紫の絵の具が欲しいと相手に言ったら、相手はちょうど紫の絵の具は持っていないが、赤と青の絵の具を持っている、そんな状況を。この状況で、あなたは次のどちらを望むだろうか。
A: 赤と青の絵の具をそのまま両方渡される
B: 相手が赤と青の絵の具を混ぜて紫の絵の具を作ってくれ、それを渡される
私はBの方が親切だと思う。もっともそれができればの話だが。
ここでWikipediaに話を戻そう。Wikipediaが今の絵の具の話とどう関係するのかというと、それが書籍やウェブページ、論文などの多様な情報源から得た情報をうまく組み合わせてひとつの「記事」という形で新しい情報を生成しているという点で共通するということだ。並べ替えるだけでなく、あくまでも欲しいものを差し出すということにより近いことをやっているように、私には思えるのだ。
編集権の集中が問題視されているらしいWikipediaであるが、個人的にはそれとは全く別のところに深いテーマが隠されているように思える。もしもあるテーマについて、その内容をわかりやすい形で示す記事を生成するという作業を自動化することができれば、そしてさらに、それをウェブ上のすべてのテキスト情報について実行することができれば、今よりも検索の効率は上昇するはずだ。「ボロノイ図」であれば、検索すればおそらく一番上にはWikipediaの記事が出て、それを読めば「あぁ、ボロノイ図ってこういうものなのか」という風に解決に至るだろう。しかしもう少し判断の難しい問題の場合、たとえば最近毎日のように取りざたされている、舛添都知事の資金の用途と、政治家としての彼の評価といった問題を調べたい場合、私たちは検索結果として表示された複数のページの文章(たいていは大手メディアの投稿記事や一部の著名人の個人ブログなど)にくまなく目を通して、それらを頭の中でまとめあげなければならない。紫の絵の具を作るのは私たちの側であって、検索エンジンの側ではない。
もちろん、ある種の嗜好を持つ人間にとっては、人間の側で判断を下すから意味があるのであって、舛添都知事についての政治家としての力量の判断まで機械任せにするようでは人類はおしまいだということになるのだろう。しかし政治や経済、社会に関する話題の多くは、毎日のように色々な人間が生み出す記事の山によって、何が本当に知るべき情報であるのかということを判別するのが難しくなっているように思う。多くの人にはそんな判別を行うに十分な時間もない。私などは情報が多すぎて、記事自体を読む樹が失せてしまうこともしょっちゅうある。結果的にはある話題について、何の情報も得られないままということになってしまう。情報だけは山のようにあるのに、なんとももったいない話である。